Knowledge Stack & Index (全記事一覧)
本ページは投稿記事一覧です。
- Architecture
- MicroArchit
- マイクロサービスアーキテクチャ メモ (2022/05)
- 【マイクロサービス】可観測性と OpenTelemetry (基本のみ) (2022/12)
- MicroArchit
- Program
- Java
- Golang
- Golang Generics (2022/01)
- Golang コード自動生成 (2022/03)
- Golang Gorm 実践メモ&注意点 (2022/03)
- Golang ポインタ (2022/04)
- Golang 並列処理(Gorutine/Channel/WaitGroup/ErrorGroup) (2022/06)
- gRPC (by golang) (2022/05)
- Golang ビルド制約使用時の golps に関する注意事項 (2022/06)
- go-ini では セミコロンが省略される (2022/07)
- golang で windows サービス 開発 (kardianos/service の 実装説明少々) (2022/07)
- golang AST & Jennifer によるコード自動生成 (2022/08)
- Golang:API 実行 と httptest (2022/08)
- JavaScript
- JavaScript 基本 (2022/01)
- JS 高階関数 (2022/04)
- Python
- Python 色々メモ (2022/03)
- Shell
- 一定量メモリを消費させるshell (2022/04)
- shell 1行目のおまじない shebang(シバン) (2022/05)
- コードレビュー どう取り組むか (2022/02)
- Algorithm
- Development
- DDD
- DDD 実践メモ (2022/03)
- GraphQL
- GraphQLについてまとめる (2022/05)
- GraphQL 設計に関する知識メモ 【執筆中】 (2022/11)
- GraphQL Code Generator まとめ (2023/04)
- gRPC
- gRPC:buf とは、buf でできること (2023/04)
- gPRC: Protocol Buffers スタイル規約 & API ベストプラクティスまとめ (2023/05)
- DDD
- BackEnd
- ElasticStack
- Elasticsearch メモ (2022/02)
- ElasticStack
- FrontEnd
- React
- React 基本概念等 (2022/04)
- React スタイリング メモ (2022/03)
- React ステート管理 (TypeScript コード例) (2022/04)
- React 副作用/メモ化/レデューサー (TypeScriptコード例付) (2022/04)
- React コードフォーマット(ESLint + Prettier + TypeScript) (2022/05)
- React Drag & Drop メモ (2022/05)
- Redux 基本 (2022/07)
- React 実践のために調べまくったこと書き綴り まとめメモ (2022/07)
- urql による Github & Gitlab の マルチクライアント 実現(サンプル) (2023/02)
- React + GraphQL + Pagination 実装 & コンポーネント分割 (2023/08)
- フロントエンド 技術要素概要集 (2022/03)
- storybook チュートリアル & CDD(コンポーネント駆動開発) (2022/07)
- フロントエンド E2E テスト + MSW (Playwright/Cypress 試行) メモ (2022/11)
- React
- Infra
- Docker
- Docker メモ (2022/05)
- RPM Tips Stack (2022/05)
- Docker
- Web
- Git
- Github
- Github プロフィールのカスタマイズ (2022/08)
- Git 追跡解除 (2022/01)
- Git Tips Link Stack (2022/05)
- Github
- VSCode
- VSCode Markdown (2022/05)
- Tools
- Roadmap
- Management
- StudyMeeting
- データ指向アプリケーションデザイン 勉強会メモ (2023/02)
- 分岐を低減する interface 設計 勉強会メモ (2023/03)
- Job
- Career
- Portfolio
- 個人用ドキュメント&ブログ管理ツール(ガチめ)作成記 (2022/01)
- 【gRPC】Connect が作られた背景概要/これまでの gRPC-Web/Connect でできること (2022/09)
- 某社フロントエンドコーディング試験を題材とした React 学習記(作成時の考慮事項まとめ) (2022/11)
- Poke Battle Integration App 再設計&今後の方針 (2023/01)
- Git Review Comment Acumulator 企画/設計 (2022/12)
- Others
- Product Manage
- プロダクトマネジメント Link Stack (2022/05)
- Refactor
- Refactor Diary 1 (Java: APIレスポンス解析) (2022/05)
- 振り返り
- 2022 振り返り (2022/12)
- エンジニアを分類する3タイプから考える自身のタイプとその先と (2022/03)
- はてなブログ投稿自動化 メモ (2022/05)
- OpenID Connect 概要まとめ (In progress) (2022/05)
- Product Manage
※ 自作ツール(Githubリンク) により本ブログへの投稿/更新はほぼ自動化 諸事情により自動更新停止中
Java 関数型インターフェースとラムダ式の簡易イメージ&StreamとJava11以降の機能との組み合わせ
関数型インターフェースとラムダ式の簡易イメージと、 StreamとOptional の簡単な例、Java11以降の機能との組み合わせを記す。 .
関数型インターフェース、ラムダ式
関数とは
ざっくり言えば、何かしらの「入力」を与えると、何かしらの「出力」を返すもの。

副作用のない小さな関数を数珠繋がりにして処理を組み立て最終的に得たい出力を得る、というのが関数型プログラミング(ざっくり言えば)

Javaの関数型インターフェースやラムダ式は、関数型プログラミング的な考え方を使うに導入された仕組み
(List などの Colletion の要素を処理するのに、関数型プログラミングは相性が良いから)
関数とJava
関数型プログラミングの概念を組み込むためには関数を宣言し受け渡しできる必要があるが、
Javaの世界では必ずコードをClassの中に書かなければならない制約がある。
そこで、関数をクラスで宣言し、オブジェクト化として受け渡しできるようにした。
Javaの世界で型が必ず必要なので、関数を表現するために、関数の型をインターフェースで表現した。その型が関数型インターフェース。
関数型インターフェースを実装(implements)して定義したものが関数(実態はクラス)。毎回関数を定義するためにクラスを実装するのは手間なため、省略して書けるようにしたのが ラムダ式
といった感じ。
関数型インターフェース
関数の型を定義したもの。
引数がいくつあり、引数の型は何で、戻り値があるかないか、戻り値の型が何か。
使われそうなものはJavaの標準ライブラリに既に用意されている(独自に定義して使用することも可能)
※昔よく使っていた、関数型インターフェースの一覧がまとまっているサイト https://www.ne.jp/asahi/hishidama/home/tech/java/functionalinterface.html
ラムダ式の実態
// ラムダ式 Function<Integer,Integer> f = x -> x * 2; // ↑ を全く省略せずに書くと以下 class Func implements Function<Integer,Integer> { @Override public Integer apply(Integer x) { return x * 2; } } Function<Integer,Integer> f = new Func<>();
匿名クラス(無名クラス)
一々別個にクラス宣言せずに処理中に関数を宣言できるようにするための仕組み ※そうそう使わない、ラムダ式を実現するための仕組みのようなものなので理解しておけば十分レベル。
import java.util.function.Function; public class Demo { public static void main(String[] args) { // 匿名クラス Function<Integer,Integer> f = new Function<Integer,Integer>() { @Override public Integer apply(Integer x) { return x * 2; } }; // Function<Integer,Integer> f = x -> x * 2; を定義しているのと同義 System.out.println(f2.apply(10)); // 20 } }
Stream (イメージ)
Streamは数珠繋がりでデータを処理するための枠組みを提供してくれている。
List<Integer> numbers = List.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10); List<Integer> squaresOfEvens = numbers.stream() .filter(n -> n % 2 == 0) .map(n -> n * n) .toList();
それぞれ決まった型の関数を渡せば、それに従って処理してくれる(各要素を Stream という副作用のない器に詰めて。※foreach等一部副作用を許容するものあり)
- map() や filter() に渡す関数の型: Function

Stream 例
中間操作
map/filter
// [trades.csv] // time,symbol,price,size // 2025-04-28T09:00:00,7203,2021.5,100 // 2025-04-28T09:00:01,9432, 98.0,200 // ... double sum = 0.0; int count = 0; try (BufferedReader br = new BufferedReader(new FileReader("trades.csv"))) { String line = br.readLine(); // ヘッダ除去 while ((line = br.readLine()) != null) { String[] col = line.split(","); // 行 → 配列 変換 if (col.length < 3) continue; // 最低限の形式チェック double price = Double.parseDouble(col[2].trim()); if (price > 100) { // 条件抽出 sum += price; count += 1; } } } catch (IOException | NumberFormatException e) { throw e } double avg = count == 0 ? 0 : sum / count; // 平均算出 System.out.printf("Avg price >100 = %.2f%n", avg);
// [trades.csv] // time,symbol,price,size // 2025-04-28T09:00:00,7203,2021.5,100 // 2025-04-28T09:00:01,9432, 98.0,200 // ... double avg = Files.lines(Path.of("trades.csv")) .skip(1) // ヘッダ除去 .map(line -> line.split(",")) // 行 → 配列 変換 .filter(col -> col.length >= 3) // 最低限の形式チェック .mapToDouble(col -> Double.parseDouble(col[2].trim())) // 価格列抽出 .filter(price -> price > 100) // 条件抽出 .average() // 平均算出 .orElse(0); // 結果が無い場合 System.out.printf("Avg price >100 = %.2f%n", avg);
flatmap
// Item(String name, int amount) {} // Order(int id, List<Item> items) {} List<Order> orders = List.of( new Order(1, List.of(new Item("Apple", 300), new Item("Banana", 200))), new Order(2, List.of(new Item("Carrot", 500))), new Order(3, List.of()) ); System.out.println("flatMap(): " + orders.stream() .flatMap(o -> o.items().stream()) // Stream<Item> .map(i -> i.getAmount() * 1.08) .collect(Collectors.toList())); // flatMap(): [324, 216, 540]
reduce
reduce(identity, accumulator): 単一の集約値
// 売上リスト List<Double> prices = List.of(120.5, 98.0, 230.0, 150.0); double total = prices.stream() .reduce(0.0, // identity (sum, p) -> sum + p); // accumulator System.out.printf("Total = %.2f%n", total); // Total = 598.50
reduce(BinaryOperator): 最大/最小・要素同士の比較で 1 つ選ぶ
Sale(String id, double amount) {} List<Sale> sales = List.of( new Sale("A", 150), new Sale("B", 420), new Sale("C", 310)); Sale max = sales.stream() .reduce((s1, s2) -> s1.amount() >= s2.amount() ? s1 : s2) .orElseThrow(); // 空なら例外 System.out.println("Max sale = " + max); // B/420
Collectors
Streamの終端子 collect() とセットで使うもの
https://docs.oracle.com/javase/jp/21/docs/api/java.base/java/util/stream/Collectors.html
※Listは 専用終端子 toList() があるため省略
toSet / toUnmodifiableSet
Set<User> active =
users.stream()
.filter(User::isActive)
.collect(Collectors.toUnmodifiableSet()) // 変更不可なSet
// .collect(Collectors.toSet()) // 変更可なSet
toMap / toUnmodifiableMap
Map<String, Employee> byId =
emps.stream()
.collect(Collectors.toUnmodifiableMap(Employee::id, e -> e)); // 変更不可なMap
// .collect(Collectors.toMap(Employee::id, e -> e)); // 変更可なMap
groupingBy() : グルーピング
- mapping() : Mapへグルーピング
Map<Deptartment, List<String>> namesByDepartment =
employees.stream()
.collect(Collectors.groupingBy(
Employee::department,
Collectors.mapping(Employee::name, Collectors.toList())));
- counting() : グループのカウント
Map<Department, Long> headcount =
employees.stream()
.collect(Collectors.groupingBy(
Employee::department,
Collectors.counting()));
partitioningBy() : 二分化
条件を満たすもの(True)、満たさないもの(False) でMapに分類
Map<Boolean, List<Employee>> seniority =
employees.stream()
.collect(partitioningBy(e -> e.years() >= 20));
joining() : 結合
// employees: Alice Bob Charlie String csv = employees.stream() .map(Employee::name) .collect(joining(",", "\"", "\"")); // "Alice,Bob,Charlie"
Optional 例
Optional も Stream 同様の操作ができる
// User → Address → City を取り出す三段ネスト String city = null; User u = repo.find(id); // null かもしれない if (u != null) { Address a = u.getAddress(); // null かもしれない if (a != null) { city = a.getCity(); // null かもしれない } } System.out.println( city != null ? city : "unknown");
↑ をOptionalを使用すれば
String city =
Optional.ofNullable(repo.find(id)) // Optional<User>
.map(User::getAddress) // Optional<Address>
.map(Address::getCity) // Optional<String>
.orElse("unknown"); // デフォルト値
System.out.println(city);
Optional を Stream で扱える(これが強力)
List<Optional<String>> optionals = List.of(
Optional.of("apple"),
Optional.empty(),
Optional.of("Banana"),
Optional.of("cherry"),
Optional.empty()
);
// Stream と Optional.stream() で「存在する要素だけ」抽出 → すべて大文字にして回収
List<String> fruits = optionals.stream()
.flatMap(Optional::stream) // 空 Optional を自動スキップ
.map(String::toUpperCase)
.toList();
System.out.println(fruits); // [APPLE, BANANA, CHERRY]
Java11 以降で追加されたStreamの機能
Predicate.not()
Java11
Stream<String> s = ...; long nonEmptyStrings = s.filter(Predicate.not(String::isEmpty)).count();
https://stackoverflow.com/questions/21488056/how-to-negate-a-method-reference-predicate#:~:text=
String.lines()
Java11
String str = " Tutorialspoint \n is \n a \n reputed \n edTech \n company "; Stream st = s.lines(); List<String> lines = st.map(s -> s.trim()).toList(); System.out.println(lines);
https://docs.oracle.com/javase/jp/16/docs/api/java.base/java/util/stream/Stream.html#toList())
Collectors.teeing()
java12
2つの収集処理を並行して行い、第3引数の合成関数でマージする
var nums = List.of(12,32,21,13); // 値の範囲を文字列で出力する String result = nums.stream().collect( Collectors.teeing( Collectors.minBy(Integer::compareTo), Collectors.maxBy(Integer::compareTo), (min, max) -> min.get() + " ~ " + max.get())); System.out.println(result); // 12 ~ 32
https://www.somuriengineer.com/2019/09/14/今更ながらjava12の新機能をまとめてみた/#:~:text=Collectors-,teeing()の追加,-メソッド定義は%E3%81%AE%E8%BF%BD%E5%8A%A0,-%E3%83%A1%E3%82%BD%E3%83%83%E3%83%89%E5%AE%9A%E7%BE%A9%E3%81%AF)
Stream.toList()
Java16
※変更不可のリストを返す(実質 .collect(Collectors.toUnmodifableList()) と同じ)
List upperCaseStrs = Stream.of("a","b","c").map(String::toUpperCase).toList(); System.out.println(upperCaseStrs); // [A, B, C]
Stream.mapMulti()
Java16
filter と 変換 をセットで行ったり、逆に要素を増やすこともできる
第2引数の Consumer(通称 sink)の acceept() に通したものだけが、次段のStreamに渡される
Stream.of("Java", "Valhalla", "Panama", "Loom", "Amber") .mapMulti((str, sink) -> { if (str.length() >= 5) sink.accept(str.length()); }) .forEach(System.out::println); // 8 6
Stream と組み合わせられる機能
Records
RecordのリストをStreamで捌け、 データを処理する際、一時的なデータ保持用の入れ物して扱ったりできる
record Pair<A,B>(A first, B second) {}
// メソッド内のストリームで使用
List<String> words = List.of("apple", "banana", "cherry");
var result = words.stream()
.map(w -> new Pair<>(w, w.length()))
.filter(p -> p.second() >= 6)
.map(Pair::first)
.toList();
System.out.println(result); // [banana, cherry]
Text Blocks
テキストブロックを行単位で処理できる
String data = """ Alice,30 Bob,25 Charlie,35 """; List<String> names = data.lines() .map(line -> line.split(",")[0]) .toList(); System.out.println(names); // [Alice, Bob, Charlie]
Sealed Classes
Stream<SuperClass> を扱うときに、instanceof のパターンマッチングと組み合わせやすくなる
sealed interface Shape permits Circle, Rectangle {} record Circle(double radius) implements Shape {} record Rectangle(double width, double height) implements Shape {} List<Shape> shapes = List.of(new Circle(2.0), new Rectangle(3.0, 4.0)); // Stream で Circle だけ抽出 List<Circle> circles = shapes.stream() .filter(s -> s instanceof Circle c) .map(s -> (Circle) s) .toList(); System.out.println(circles); // [Circle[radius=2.0]]
サブタイプごとでグルーピングもできる
Map<Class<? extends Shape>, List<Shape>> byType =
shapes.stream()
.collect(Collectors.groupingBy(Shape::getClass));
※Sealed Classes の詳細は JavaのSealed Classesについて 参照
個人ドキュメント&ブログ管理ツールのリメイク(関心の分離の追求)
まだちゃんと動かしてないため完成してはいないが、一通り実装しきったので投稿。
リメイク背景
自分の (ドキュメントとは言えないレベルの) 書いた物を管理する上で、ローカルとブログ(はてなブログ)やその他など複数個所で管理するのが面倒になったことと、引き出しやすさを特に重視したかった。 そのために、以下を実現できるものを作ることを考えた。
- 自分が書いたものを1か所で管理したい。外に見せる物はブログにも投稿するようにしたい
- ※原本は
- 記事の一覧をカテゴリごとで分類したツリー構造の形式で一覧を見れるようにしたい(ため自動で生成する)
- ※ローカルとブログどちらにも、それぞれ用意する
実際に、自分ルール(複雑化を防ぐ目的での制約)を設けて作ったのが以下。
このツールを作成してから記事を書く際には VS Code を使用していたが、書く部分とプレビュー部分が分かれることや、作業用のフォルダと記事格納フォルダが完全に分けていた点など使いにくさを感じるようになった。そんな時にObsidian に出会ったことにより、Obsidianの書き心地の良さと、タグでの管理方法も取り入れたいと思ったことから、Obsidianを使うようになった。
それ故に、普段はObsidianを使うがブログに投稿する場合のみ旧ツールを使うという本来の目的からは逸脱した運用になった(そしてツールは使わなくなった)。そのため、本来の目的に沿った状態に変える(戻す)必要があった。 また、前回のツールを作る上で設けてしまった制約がObsidianを使用することを前提に考えると邪魔な物となり、ルールを変える必要があったため(一部使い回せるコードはリファクタして再利用しつつ)、作り直した方が良いと考えてリメイクすることとした。
リメイクで実践したかったこと=「関心の分離」の追求
前回作成時は、トップのパッケージ構成を以下のレイヤー(infrastructure層だけはアクセス先ごとでパッケージを分けた)+横断的な物で分けていた。
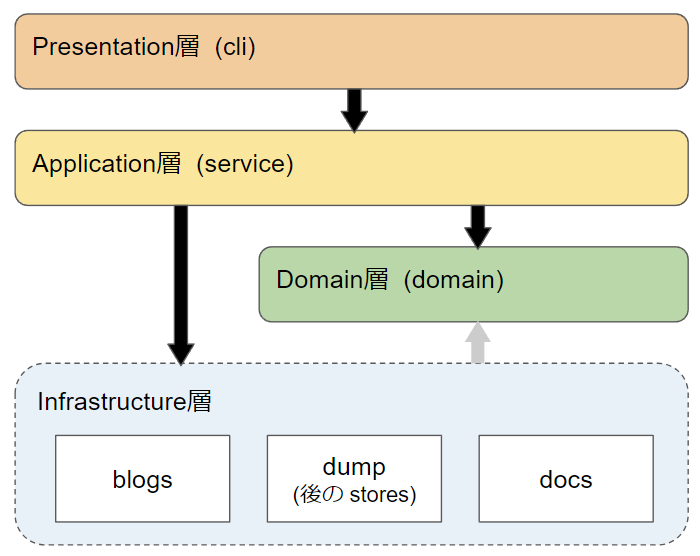
今回は、パッケージ構成を(アプリケーションが扱う)関心事+横断的な物とした(正確には途中までトップをレイヤーベースのパッケージ構成で開発を進め、終盤で関心事ベースに変更した)。 また、具体物は後述するが、複数の関心に跨るものと複数の関心に共通するものを別のパッケージとして明確に分離した。 ※今回のパッケージ構成は次節参照
レイヤーの依存関係も、前回作成時はApplication層からInfrastructure層への依存関係があったが、そこも無くして以下とした。

そうやって、関心の分離を進めていくことで、以下の恩恵を感じた。
- 頭の中で描いていたそれぞれの関心の境界と、ソース上の境界(パッケージ)が一致して全体の把握や確認がより直感的になり分かりやすくなった。
- 各関心間の依存関係の管理がしやすい(途中までレイヤーベースのパッケージ構成で実装を進めていた際に循環参照を作りこんでいたが、その修正もしやすかった)。
- インターフェースが他の関心との境界として機能している感を得られた(インターフェースが各関心の独立性に直結している)。
- domain層に Infrastructureのインターフェースを置いているが、そのインターフェースも含めて
- (恐らく適切に)それぞれの関心の独立性を高くすることができた
- 変更の影響範囲を限定しつつも、影響を受けるべき所には影響が及ぶ作りにできた。
- それぞれの関心ごとのユースケースを意識して分けることができ、個々がシンプルになった。
詳細設計概要
今回作った物(リメイク版): https://github.com/Symthy/obs-docs-blog-entries-manager
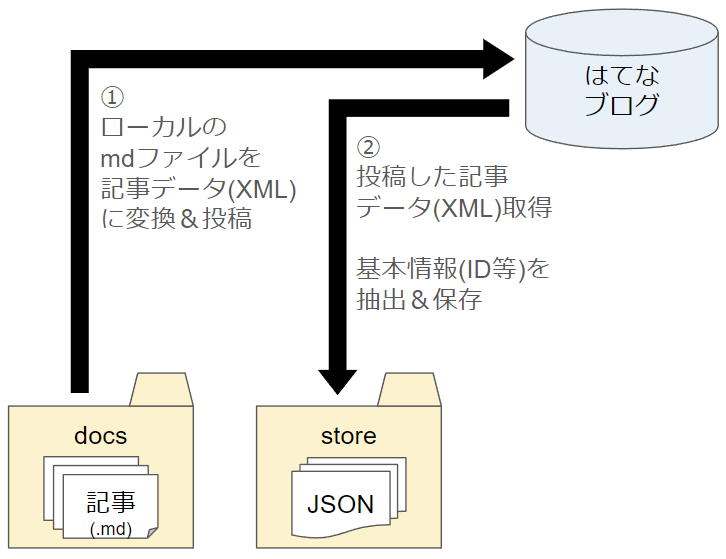
大まかなデータフロー
ローカルの記事を ブログに投稿する場合
ブログから記事を取得してローカルに保存する場合
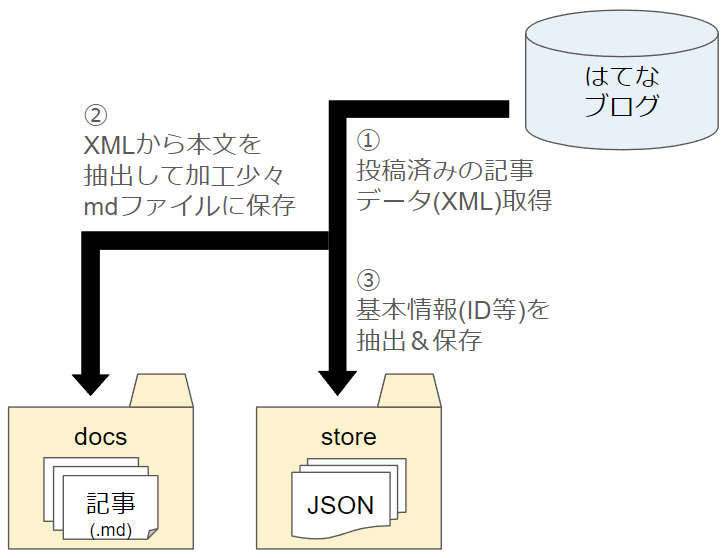
※ローカルのドキュメントのフォルダ構成は、前回作成ツールではカテゴリ定義ファイルで定義するようにしていたが、今回は定義ファイルを無くして各ドキュメントに付けたタグ( #xxx, #xxx/yyy )のパスに基づいてフォルダ階層の構築とフォルダへの配置を行うようにした。
パッケージ構成
主要なパッケージと依存関係は以下の通り。

複数(blogsとdocs)の関心に跨るもの(composites) と 複数(blogsとdocs)の関心に共通する物(entries)を追加した。
compositesに分けることによって、blogsとdocsにそれぞれに変更があった際にお互いに影響を与えないが、両者を利用する部分には影響が及ぶ部分を隔離した。 entriesに分けることによって、blogsとdocsそれぞれを管理する上で必要になる stores のロジックへのインターフェースしての役割をentriesが担うことで、storesの部分を共通部品とするだけでなく独立化した。また、両者に共通で必要になる値オブジェクト等をまとめた。 これにより、blogsとdocsの境界が明確になり、これらの独立性の確保にもつながった。
大まかなクラス構成(&レイヤーベースのサブパッケージ)
各パッケージ内のサブパッケージ(レイヤーベース)とクラスは以下の通り。
※主要なもののみに限定。分かりやすさ重視で諸々省略。composites.usecase -> docs.domain.DocEntry, blogs.domain.BlogEntry の依存関係があるが線がごちゃつくため省略

※上述のパッケージ図の通りの依存関係かの確認のために作成。実際には各パッケージには↑の図より多くのクラスがあるが、関心事ベースのパッケージ構成に変えてからパッケージ間の依存関係が想定通りかの確認が各段にしやすくなった。
おまけ: 2024/10/13時点のステップ数&ファイル数
| パッケージ | ファイル数 | ステップ数 |
|---|---|---|
| composites | 16 | 510 |
| blogs | 35 | 991 |
| docs | 32 | 955 |
| entries | 11 | 507 |
| stores | 9 | 218 |
| その他全て | 27 | 609 |
| 合計 | 130 | 3790 |
最後に
テスト容易なコードを書ける自分が関心の分離を追求し、関心事ベースのパッケージ構成にしてみて思ったことは以下の通り。
- 保守性を高めるために、他へ影響を与えないように作る。のではなく、それは前提にしつつ、影響が及ぶべき所 (変更が必要な箇所) には影響が及ぶ (その範囲は適切に限定する) ように作るが良し。
- アプリが扱う物事(≒関心事)と、ソース全体を俯瞰した視点(パッケージレベルの視点)での依存関係が一致するというのは、アプリが扱う物事をより人が理解しやすくなる (視覚的・論理的に一致するから?)
関心の分離を徹底することは、上記に繋がると感じた。 そして、たかが4Kstep弱のツールではあるが今回はそれができた(と思っている)。
2023振り返り&転職活動記
2023振り返り&転職活動記
2023年総括
1年前に色々と目標を立てた気がしますが、転職活動にかかるコストの見積もりが甘すぎました(反省)。 今年1年ほぼほぼ「転職」+「自己理解」にリソースのほぼ全てを持っていかれましたが、その甲斐もあり自分にとって良い企業とご縁がありました。 なんとか無事に、2023/11末をもって前職(SIer)を退職し、2023/12から中小の自社開発企業に転職できました。
今年1年の業務面振り返り(ネガティブ要素あり)
年初~2023/11 までの前職についての振り返り。 ※ネガティブな要素が多いので、気分を害したくない方は読み飛ばしてください。 ステータス:某メーカー系SIerの子会社で、職種:SEではあるけど、4年ほど親会社のプロダクト開発に参画してスクラムちっく(Sprint回すけど後ろの期限は動かない)な環境で開発やっていました。
業務面では(自分含めた4人チームの) 半分リーダー?としてチームのタスク管理/スケジュール管理+メンバーの面倒を見る+コーディングレビューが主でした。が、ちょうど新規参画者2人が入る、かつ蓋を開けてみれば現場の技術セットにほぼ合わない故に、何かあれば自分が無茶をしてなんとかせざるを得ない負荷集中マッハの状態でした。それも相まって、モチベーションの維持も難しく、自然と残業も多くなり(これは元から)、仕事が終わればストレス過多の状態を消化すしつつ転職活動するような日々でした。故にプライベートで学習したりコード書いたりする時間がここ数年のうちで断トツ少ない年でしたので成長実感もあまりない1年でした。
(半分)リーダーとして、何か成果を上げられたかというと「無い」という回答になります。 理由は単純。スクラムっぽくやっているものの期限は厳しい現場の中で、明らかチームの戦闘力不足かつ自分が頭2つ3つ飛びぬけているアンバランスなチームであったため、自然と自分が色々カバーせざるを得ませんでした。本当はタスクをメンバーに委譲して任せたかったが、(特に実装となると)実力不足によりSprint内で終わらなくなる状況は頻発し、期限に間に合わないとなれば最悪タスクを奪って自分がやっていたため、メンバーに成功体験をあまり積ませられませんでした。また、技術への理解や遂行力的に明らかに任せられないものは自分がやらざるをえないような負荷集中状態でしたので、自分のリソースが足りず、チームビルディングも半ば放棄していましたし、典型的な人に任せられない&メンバー信用できないダメリーダーをやっていた(そうでもしなければ回らないし間に合わないと本気で思っていた)からです。
自分の「責任感」「分析思考(理性>感情)」の資質が完全に悪い方向に出まくっていました。 本当はトップダウン的なチーム構造にはしたくなく、フラットな構造にして自分が先頭に立って引っ張るよりも縁の下の力持ち的な立ち回りが自分らしいと思いながらも、トップダウン的にやらなければまともに回りませんでした。昨年までサブリーダーとして多少なりともリードエンジニアを意識した縁の下の力持ち的な立ち回りをしていた時よりも、リーダー?というポジションに拘束されてしまい、サブリーダーの時に発揮していた物も損なったような感覚が強く、現状を打破する手も見つからず終始苦しんでいました。
この1年間の学びとしては、実際にリーダー?をやってみて、マネージャーに向いてない人間がマネジメント的なことをするとどうなるかを実体験できたことは収穫だったと思います。やはり自分はマネージャーの方向には行きたくない、行くべきでないという結論が実体験を通して確信に変わりました。 また、典型的なトップダウンの業界構造/組織の中で、またリーダー的なことをやることになった際には、恐らく同じようなことを繰り返してしまうことが想像に難くないため、自分はそういった環境は避けた方が良いということです。なによりも自分にあった環境どうかが非常に大事だということを転職をして学びました(肩肘張らず、素のフラットな自分でいられる環境かどうかというのは本当に重要だと思います)。
転職活動記
今回色々な方の力を借りながら、ちゃんと転職活動をやってみて、「転職活動」という言葉自体が不適切だと感じました。 個人的には「人生を見つめ直す活動」の方が適しているのではないか、「転職活動」という言葉がその本質を見失わせているのではないか、と思いました。
(自分が30代前半というステータス(30代の転職は居場所探しというのをどこかで聞いた)だったり、これまで働きすぎて (お世話になったエージェントさんに言われた(苦笑) )、若干健康を損ねてしまったのもあり、今後あまり無茶ができないためワークライフバランスを重視していた部分もあるかもしれませんが)
自分の本音と正面から向き合いながら
- 自分の「人生の軸」が何だから、こういったキャリアパスを目指す、自分の軸と重なる企業を目指す
- 自分と合う企業はどういう環境(風土)か
そういったことを整理/言語化して、自分の今後の人生のために適した場所を探す活動だと思い直しました。
転職活動の中盤までは、「自分の人生の軸が〇〇だから、この企業を志望する」というのがあまり言語化できておらず、お見送りが続きました。が、とあることをきっかけに言語化できるようになってからは、それまでより自信をもって面接に臨むことができ、最終的に内定を2社からいただくことができました。
転職理由
8年半強いた前職についてと、転職理由について記載します。
前職は、某メーカー系SIer の 子会社(主に親会社からの2次請け)で、システムエンジニアをしていました。正直理由はSIerあるあるだと思います。面接では出さなかったネガティブ面も全て記載します(こういう裏事情もありましたということで、ポジティブ面と若干被ってる部分ありますが)。
ポジティブ面:
- マネジメント前提の道しかなく、技術の方向を目指したいが、それが困難であること
- (ありがたいことに親会社のプロダクト開発に参画させて頂いたが) プロダクトを使うユーザの声や要望が全く降りてこず、どういったものを作るのが真にユーザのためになるか分からないため、そういったものが開発現場まで降りてくる環境で開発に没頭したい
- 改善に回すリソースがほぼなく、改善の提案/実行自体が難しいため、改善にも取り組んでいる環境で働きたい
- 頼れる仲間と一緒にお互いリスペクトし合いながら働きたい
ネガティブ面:
- 期限が厳しいので基本的に残業が多くなりがち(1年目で1回100h行ったり、2~3年目の銀行系は平均60h位あったり、直近4年は毎月ほぼ40h時々60h弱だったり)
- (周囲と比べて自分が頭2つ3つ抜けていた状態だったので) 周りに頼れる人がいなく孤独感が強い
- 技術力の低い人、向上心の低い人などの面倒を今後も一生見続けなければならないこと
- (転職するために) 29歳から3年足掻き続けた結果、この先前職で働き続けることが難しいと判断したこと
- 上述の事項によりモチベーション維持が3年で限界を迎えた。かつ、ネガティブな感情ばかりで精神的にも苦しかった
- (生活に支障が出ているわけではないが) 無理がたたって多少健康を損ねてしまった
- 以上により、このままだと定年迎えるより先に心身どちらか壊してドロップアウト一直線
- (お分かりかと思うが) 新卒で入る会社をそもそも自分がミスっていた
転職活動準備~始動まで(2023/1~4)
準備期間が長くないかと、これには理由があります。。時系列順に
職務経歴書作成(2023/1~2)
まず、職務経歴書の作成を行いました。その際、Findy様のユーザアクセス面談 に大変お世話になりました(改めてお礼を申し上げます)。 作成には1ヶ月強程かけてしまった気がします。キャリア感の壁打ちや書類に関してのアドバイス、企業の紹介など、本格的に転職活動を始めてからも手厚いサポートいただきました。 この時は、今後のキャリアとして、SIerでのサブリーダ経験という社会から求められていることと、本当は手を動かし続けたい/技術の方向に行きたいという自分の願望の間を取る形にしていました。
応募ボタン押せない事件
書類作成もでき、何社か応募しようとしました。ですが、できませんでした。 自分の本音を無視することができず精神的な限界を迎えたからです。 本心は、マネジメントの方向を目指したくないにもかかわらず(転職が目的化していたが故に)マネジメントの方が求められているから、そこに多少寄せる。というのが、(幸いにも)できるだけの精神的余力がなく、ここで一度立ち止まりました。
転職支援サービスへ(2023/3~)
立ち止まった時、そもそも自分は周りとは何かが違うんじゃないか?という疑問がふと湧きました。巷に聞く発達障害ではなさそうだったので、色々探す中で HSP(Highly Sensitive Person)という言葉に出会いました(見つけた時は、ああこれだ。となりました)。 HSPというキーワードを元に探した結果「マジキャリ」という転職支援サービスに出会いました。 独りでは、現状を打破することができなかったので、藁にも縋る思いでお金を払って利用することにしました。担当頂いたコーチの方には最初「自己肯定感」が低すぎると言われました(それぐらいボロボロな状態でした)。1ケ月強かけて過去を振り返り、自分の本心と向き合いながら「自己肯定感」を上げるための取り組み(本を紹介頂いたり、毎日頑張ったことを3つ書く日記を付けたりなど)も帆走いただきました。 そのおかげで、5月を迎える頃にはなんとか行動に移せるくらいには精神が回復しました。
転職活動 応募~内定まで(2023/5~9)
7月末くらいまでは、転職支援サービスの方に帆走いただきながら進めました。 また、Laprasキャリアの方にも非常にお世話になりました。紹介頂いた企業以外についても面接が終わる度に直接会話して思考の整理に付き添ってくれたりと、手厚くサポートしていただきました。この方との出会いがあったからこそ、自分には (ドライとは逆の)「ウェットな環境」な風土の企業が合うということを見出せたと思います。
ただ、それだけでは足りませんでした。 8月に入るまで自分の「人生の軸」を言語化できていなかったが故に(聞かれた企業あまりありませんでしたが)志望理由が毎回上っ面のものしか用意できませんでした。(企業選びもエージェントに紹介されたものやスカウト頂いた物で直感的に選んでいたと思います) そんな状態だったため、7月に受けたとある企業で、「なぜうちか?」というのを問われた際に、上手く回答できませんでした。
そんな中、たまたまyoutubeで 八木仁平さんの自己理解チャンネル に出会いました。 (当時) 無料配布されていた自己理解ワークや、それうちじゃなくてよくない?と言われない志望動機の作り方徹底解説 の動画で、配布されていた志望動機テンプレートを通すことで、自分の「人生の軸」をある程度言語できたため、以降の面接はある程度自信をもって臨むことができました。
その甲斐あって2社から内定を頂き、エージェントさんと一緒に以下のような項目で自分なりに企業比較を行って現在の会社の内定を承諾するに至りました。
- ミッション/ビジョン共感
- プロダクトの魅力
- 仕事内容
- 年収
- 将来性
- 面接での雰囲気
- 一緒に働きたいと思う社員はいたか?
- 業務のスピード感
- 労働環境
- 自己成長
自分にはスタートアップ/ベンチャーは向いていない
(こういった場で勝手に名前を出していいか分からんので伏せますが)、Lapras経由でスカウト頂いた某スタートアップ企業に応募し、最終選考まで通していただけましたが、最終的にはお見送りという結果になりました。ただ、ありがたいことに、(特にこちらから聞いたりもしていないのですが) 頂いたメールには、以下のお見送り理由も記載いただけていました。
「営業側と跨いで密な連携が必要になったり、必然的にマルチタスクが生まれたりと状況が刻々と変わっていくので、本来のパフォーマンスを発揮いただくには、もう少し後のフェーズの方が、気持ちよくご活躍をいただけるのではという結論に至りました」
自分の場合は、どちらかと言えば独りで黙々とやりたいタイプで、マルチタスクできるけど得意でもない(正確性などが犠牲になる)人間です。それを面接の中で(ストレートにではないものの)、得意/不得意を聞かれて、ありのままお伝えしたからこそ、こういったフィードバックになったのだと思います。
このフィードバックには非常に納得感がありましたし、頂けたことで自身がスタートアップ/ベンチャーには向いていない(目指すべきではない)と確信を持てました。また、企業のフェーズ的にそれなりに年数のたった中小企業が自分には良いという裏付けにもなりました。
(このフィードバックを頂けたことには感謝してもしきれません)
余談:内定承諾後~退職/入社後 (2023/9~2023/12)
前職退職(11月末)まで、もめたりとかは全くなかったものの、一波乱ありました。 9月上旬に内定を頂いて、(業務状況的に10末は難しいと判断して11末退職希望で)、次の日に上司に伝えて、その次の日には課長と面談してと、話はトントンと進みました。 最初は、退職日まで2ケ月もあるので、1ヶ月後くらいにはリーダーを誰かに引き継いで軌道に乗る位まではサポートして終盤は裏方に徹しようと画策していました。
が、退職を伝えた次の週、私の上司が交通事故にあい、入院して戦線を離脱。空いた穴を埋めるために9月後半~10月まで負荷集中マシマシでした(なぜ退職する人間が引き継ぎ関係なしに退職前月に残業60h弱もやっているんだろうと当時は思ってました笑)。 結局まともな引継ぎらしい引継ぎもできず(とはいっても、自分がチーム内のwikiの発起人で以降勝手に管理していたので情報は大体残せていたのでやることあまりなかったというのはありますが)、有休消化期間は1週間、最終出社日までフル稼働し業務を区切りよく終わらせて、そんな中頑張って引っ越しもするという、最後までドタバタ状態で退職し、なんとも歯切りの悪い最後でした(まぁある意味自分らしかったです笑)。
次の会社に入社して早1ヶ月経過しました(頑張って会社から2km弱の場所に引っ越した甲斐あって、QOLは爆上がりしました笑)。 「人の良さ」で選んだ所もあって、環境面に不満などあろうはずもなく、前職と比べれば劇的に改善されました。月1で 1on1 や 毎週 4~5人程のグループに分かれて良かった事など共有する会、スキルアップアクション(各々目標を決めてアウトプットする活動) などあり、とても新鮮です。 ちょっと忙しいタイミングに入ってしまったらしく、ほぼ未経験(昔個人で少し触ったかどうかレベル)の Ruby on Rails 製の物を改修することになり、(自主的というか自己責任でですが)残業25h位しましたが、「根詰め過ぎずにね」と声を掛けてくれる人がいたり、30h超えないようにしておけば大丈夫だったりと、前職常に45h弱が当たり前だったことを考えば、言葉で言い表せない位ワーク面も改善したと思います(まだまだこれからだと思いますが)。 また、この1ヶ月を通してかつ1on1で会話したりして、今の自分が(多少頑張れば)貢献できそうな目標も見つかったので、今後はそこに向けて精進したいと思います。
最後に(2024年目標)
年初に2023年の目標を色々立てた気がしますが、「転職」以外の目標は達成できていません。が、一番重要な「転職」が達成できたので個人的には十分すぎます。失ったものもありますが、転職活動を始めるまでの3年足掻き続けた甲斐がありましたし、とある方に笑顔が増えたと言っていただけた位には精神状態が改善されました(3年間はネガティブループにハマりっぱなしで抜け出す術すら見つからず苦しんでいたのが嘘かのように、そこから解放されました)。
2024年の目標として、ひとまず以下を上げておきます。
- 個人でのやりたいことを進める(技術とはあまり関係ない)
- (現職で必要なため) PHP と SQL の学習
- React の学習を継続して、個人開発を進める
- 過去に作った自分用のドキュメント管理&ブログ投稿用ツールをリメイクする
- 良いコード/テストしやすいコードを書くためのTipsをまとめる
あとは、人に頼ることを覚えることでしょうか(元から頼り下手ですが、前職で拍車をかけてしまい、まだまだ引きずっているので、今の環境であれば徐々に改善していけると思います)。 2023年はほとんど記事も書いてなかったので、2024年は上記に関連するものでいくつか記事を書けたらと思います。
以上
React + GraphQL + Pagination 実装 & コンポーネント分割
React + GraphQL + Pagination 実装 & コンポーネント分割
作成物と本記事で触れること概要
以下を使って
- React
- Mantine
- urql
- Github GraphQL API
(開発中のフロントエンドアプリ(と言うよりはツールレベル)のほんの1部品でしかないが) Github の Repository 一覧表示&Pagination ができるコンポーネントを作っている
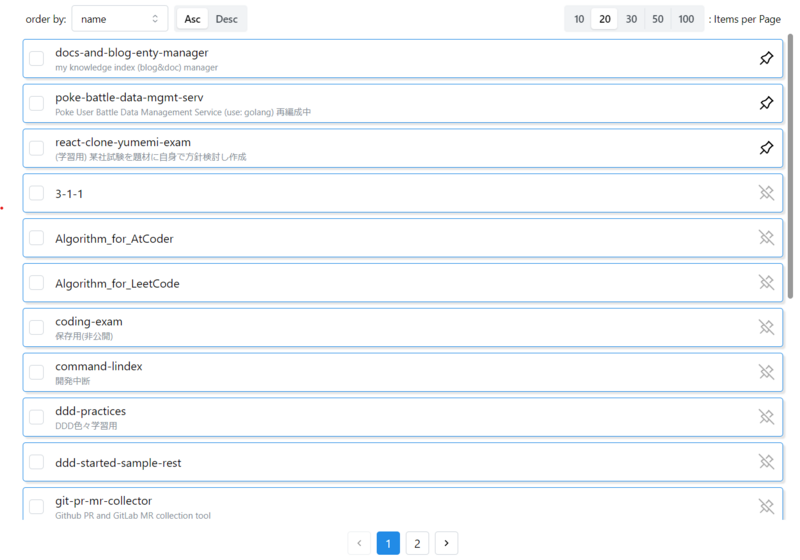
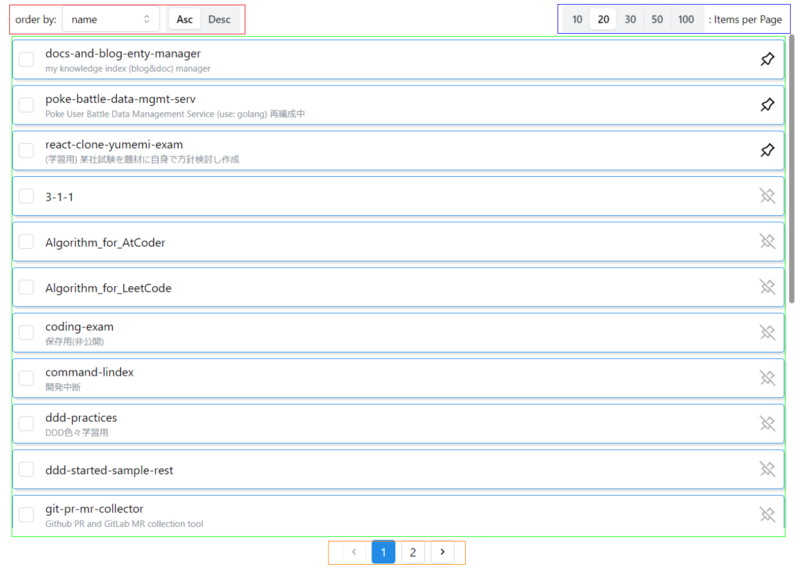
(他にももう少し機能追加したり装飾を良くする予定だが) 現時点では、pagination 以外にも
- 1 ページ辺りの表示件数変更 (右上の items per page)
- ピン留め(右端のピンを ON にすると1ページ目の先頭に固定)
- ソート(左上の order by)
をできるようにしている。これを実装するにあたって悩んだこと 以下2つに触れる
Github GrapQL API 利用での pagination 実装
今回訳あって、自前で pagination の仕組みを実装した。
Github GrapQL API さんは、そもそも pagination の仕組みをサポートしているため、以下のような指定でき、やろうと思えば簡単に実現できると言えばできる。
- 何件取得するか
- ソート
- どこから取得するか (cursor 指定)
ただし、「2 ページ先、3 ページ先、... のデータ取得」ができない(1ページ前後のデータ取得はできる)
ユーザビリティの観点から、これがアプリでできないことを許容しきれず、実現方法を考えた結果が以下3つ。
- 最初に全件取得して保持する
- 最初に全件取得して各ページの先頭の cursor を保持する(ページ遷移時は、そのページの先頭の cursor を指定して GraphQL API を実行しデータを取得する)
- デメリット:
- ソートや1ページ辺りの表示件数が変更された際に全件再取得が必要(キャッシュがあるので最初の1回のみ)
- 初めてその操作を行われた時に取得とすると、途中で Repository が作られた場合に、条件次第で表示されたりされなかったりする Repository ができてしまう (データ不整合)
- それを回避しようとキャッシュの有効期限を短くしてしまうと、操作する毎に頻繁に読込中になり、ユーザビリティが落ちる
- ソートや1ページ辺りの表示件数が変更された際に全件再取得が必要(キャッシュがあるので最初の1回のみ)
- デメリット:
- そもそも GraphQL API 使うのを諦めて REST API を使う
この中から今回は、ユーザビリティ優先で、1 点目の「最初に全件取得して保持する」とした。
デメリットの「データ多量の場合、パフォーマンス劣化に繋がる恐れがある」に関して、特に初期描画の場合、全データ取得してから読込中解除 → 操作可能としたのでは、データ多量の場合に操作可能になるまでに時間を要することが考えられる。それを回避するために以下の工夫した。
- 初回描画時、1 ページ目に表示する内容のみを取得し完了すれば読込中解除して一覧を表示。
- 全件データ取得は別途実行し、取得完了しても一覧の表示を更新しないよう
useRefを使用して保持(useRefを使用すれば更新しても再レンダリングは発生しない) - 全件データ取得が終わるまでは、(1 ページ目に表示する内容のみ取得が済めば一覧表示されるが)pagination の機能は無効化
export const CheckableLineBoxesPagination = ({
selectedItems,
setSelectedItems,
fetchFirstPageData,
fetchAllPageData,
currentViewItems, // 現在のページに表示するデータのみ持つstate
initCurrentViewItems,
updateCurrentViewItems,
children,
}: CheckableLineBoxesPaginationProps) => {
const [activePage, setActivePage] = useState(1); // 現在のページ
const [totalPages, updateTotalPages] = useTotalPages(); // ページ数合計
const [itemsPerPage, setItemsPerPage] = useItemsPerPage(20); // 1ページ辺りの表示件数
const [isLoading, setIsLoading] = useState(true);
const [enabledPagination, setEnabledPagination] = useState(false);
const allItems = useRef<CheckableLineData[]>([]);
useEffect(() => {
// 1ページ目のデータのみ取得するための処理
const initialize = async () => {
const data = await fetchFirstPageData(itemsPerPage);
if (data) {
initCurrentViewItems(data.items);
updateTotalPages(data.totalCount, itemsPerPage);
}
setIsLoading(false);
};
// 全件データ取得するための処理
const fetchAllData = async () => {
const repos = await fetchAllPageData();
allItems.current = repos;
setEnabledPagination(true);
};
initialize();
fetchAllData();
}, []);
// 省略 全体は次節参照
};
pagination + α 実装コンポーネントの分割
Before
リポジトリ一覧表示(pagination 付)の当初ソース
- 一覧表示は、PR 一覧などへ再利用したいため、汎用化。
※この時点は、ソート機能未実装で、リポジトリ名昇順固定
- repository-list コンポーネント
type Props = {
selectedRepositories: string[];
setSelectedRepositories: (items: string[]) => void;
fetchFirstPageRepositories: (
itemPerPage: number
) => Promise<{ items: CheckableLineData[]; totalCount: number } | undefined>;
fetchAllRepositories: () => Promise<CheckableLineData[]>;
};
export const RepositoryList = ({
selectedRepositories,
setSelectedRepositories,
fetchFirstPageRepositories,
fetchAllRepositories
}: Props) => {
const [pinnedRepoNames, getPinState, togglePin] = usePinnedRepos();
const sortPinnedReposToTop = (repos: CheckableLineData[]): CheckableLineData[] => {
const pinnedRepos = repos.filter((repo) => pinnedRepoNames.includes(repo.value)).sort(sortLogic);
const nonPinnedRepos = repos.filter((repo) => !pinnedRepoNames.includes(repo.value)).sort(sortLogic);
return [...pinnedRepos, ...nonPinnedRepos];
};
const [currentViewItems, initCurrentViewItems, updateCurrentViewItems] = useCurrentViewItems(sortPinnedReposToTop);
return (
<CheckableLineBoxesPagination
selectedItems={selectedRepositories}
setSelectedItems={setSelectedRepositories}
fetchFirstPageData={fetchFirstPageRepositories}
fetchAllPageData={fetchAllRepositories}
currentViewItems={currentViewItems}
initCurrentViewItems={initCurrentViewItems}
updateCurrentViewItems={updateCurrentViewItems}
>
{currentViewItems.map((item, index) => {
let marginStyle = { margin: '0.5rem' };
if (index === 0) {
marginStyle = { margin: '0.1rem 0.5rem 0.5rem 0.5rem' };
} else if (index === currentViewItems.length - 1) {
marginStyle = { margin: '0.5rem 0.5rem 0.1rem 0.5rem' };
}
return (
<CheckableLineBox
key={item.key}
value={item.value}
title={item.title}
subText={item.subtext}
style={marginStyle}
suffixNode={<TogglePin pinned={getPinState(item.value)} togglePin={() => togglePin(item.value)} />}
/>
);
}
</CheckableLineBoxesPagination>
);
};
- checkable-line-boxes-pagination コンポーネント
type CheckableLineBoxesPaginationProps = {
selectedItems: string[];
setSelectedItems: (items: string[]) => void;
fetchFirstPageData: (
itemPerPage: number
) => Promise<{ items: CheckableLineData[]; totalCount: number } | undefined>;
fetchAllPageData: () => Promise<CheckableLineData[]>;
currentViewItems: ReturnType<typeof useCurrentViewItems>[0];
initCurrentViewItems: ReturnType<typeof useCurrentViewItems>[1];
updateCurrentViewItems: ReturnType<typeof useCurrentViewItems>[2];
children: ReactNode;
};
export const CheckableLineBoxesPagination = ({
selectedItems,
setSelectedItems,
fetchFirstPageData,
fetchAllPageData,
currentViewItems,
initCurrentViewItems,
updateCurrentViewItems,
children,
}: CheckableLineBoxesPaginationProps) => {
const [activePage, setActivePage] = useState(1);
const [totalPages, updateTotalPages] = useTotalPages();
const [itemsPerPage, setItemsPerPage] = useItemsPerPage(20);
const [isLoading, setIsLoading] = useState(true);
const [enabledPagination, setEnabledPagination] = useState(false);
const allItems = useRef<CheckableLineData[]>([]);
useEffect(() => {
const initialize = async () => {
const data = await fetchFirstPageData(itemsPerPage);
if (data) {
initCurrentViewItems(data.items);
updateTotalPages(data.totalCount, itemsPerPage);
}
setIsLoading(false);
};
const fetchAllData = async () => {
const repos = await fetchAllPageData();
allItems.current = repos;
setEnabledPagination(true);
};
initialize();
fetchAllData();
}, []);
useEffect(() => {
updateCurrentViewItems(allItems.current, itemsPerPage, activePage);
}, [activePage]);
useEffect(() => {
updateTotalPages(allItems.current.length, itemsPerPage);
updateCurrentViewItems(allItems.current, itemsPerPage, activePage);
setActivePage(1);
}, [itemsPerPage]);
if (isLoading) {
// Todo
return <div>Loading...</div>;
}
if (currentViewItems == null || currentViewItems.length == 0) {
// Todo
return <div>Empty</div>;
}
return (
<>
<Flex justify="flex-end" align="center" direction="row">
<SegmentedControl
value={itemsPerPage.toString()}
onChange={setItemsPerPage}
data={itemsPerPageList}
disabled={!enabledPagination}
/>
<Text fz="sm" sx={{ marginRight: "1rem" }}>
: Items per Page
</Text>
</Flex>
<ScrollAreaWapper>
<Checkbox.Group value={selectedItems} onChange={setSelectedItems}>
{children}
</Checkbox.Group>
</ScrollAreaWapper>
<Pagination
sx={{
padding: "0.5rem 0.25rem",
}}
total={totalPages}
position="center"
value={activePage}
onChange={setActivePage}
disabled={!enabledPagination}
/>
</>
);
};
1 コンポーネントに useEffect が 3 つ…
責任分担できてなくて、ひとまとめになっている感じなので、分割
After 1
以下のイメージで部品ごとに分割を試みる
- repository-list コンポーネント
export const RepositoryList = ({
selectedRepositories,
setSelectedRepositories,
fetchFirstPageRepositories,
fetchAllRepositories,
}: Props) => {
const [currentViewItems, initCurrentViewItems, updateCurrentViewItems] =
useCurrentViewItems();
const [getAllItems, setAllItems] = useAllItemsAccessor();
const [sorter, dispatch] = useSorterReducer();
const [pinnedItemNames, getPinState, togglePin] = usePinnedItems();
const pinnedItemsToTopSorter = (
items: CheckableLineData[]
): CheckableLineData[] => {
const sortedPinnedItems = sorter(
items.filter((item) => pinnedItemNames.includes(item.value))
);
const sortedNonPinnedItems = sorter(
items.filter((item) => !pinnedItemNames.includes(item.value))
);
return [...sortedPinnedItems, ...sortedNonPinnedItems];
};
const handleClickPin = () => {
setAllItems(pinnedItemsToTopSorter(getAllItems()));
};
return (
<CheckableLineBoxPagination
allItemsAccessor={[getAllItems, setAllItems]}
selectedItems={selectedRepositories}
setSelectedItems={setSelectedRepositories}
fetchFirstPageData={fetchFirstPageRepositories}
fetchAllPageData={fetchAllRepositories}
currentViewItemsStateSet={[
currentViewItems,
initCurrentViewItems,
updateCurrentViewItems,
]}
sorterReducerSet={[pinnedItemsToTopSorter, dispatch]}
>
<CheckableLineBoxListWithPin
currentViewItems={currentViewItems}
handleClickPin={handleClickPin}
pinnedItemsStateSet={[pinnedItemNames, getPinState, togglePin]}
/>
</CheckableLineBoxPagination>
);
};
- checkable-line-boxes-pagination コンポーネント
type CheckableLineBoxesPaginationProps = {
allItemsAccessor?: ReturnType<typeof useAllItemsAccessor>;
selectedItems: string[];
setSelectedItems: (items: string[]) => void;
fetchFirstPageData: (
itemPerPage: number
) => Promise<{ items: CheckableLineData[]; totalCount: number } | undefined>;
fetchAllPageData: () => Promise<CheckableLineData[]>;
currentViewItemsStateSet?: ReturnType<typeof useCurrentViewItems>;
sorterReducerSet?: ReturnType<typeof useSorterReducer>;
children: ReactNode;
};
export const CheckableLineBoxesPagination = ({
allItemsAccessor: [getAllItems, setAllItems] = useAllItemsAccessor(),
selectedItems,
setSelectedItems,
fetchFirstPageData,
fetchAllPageData,
currentViewItemsStateSet: [
currentViewItems,
initCurrentViewItems,
updateCurrentViewItems,
] = useCurrentViewItems(),
sorterReducerSet: [sorter, dispatch] = useSorterReducer(),
children,
}: CheckableLineBoxesPaginationProps) => {
const [activePage, setActivePage] = useState(1);
const [totalPages, updateTotalPages] = useTotalPages();
const [itemsPerPage, setItemsPerPage] = useItemsPerPage(20);
const [isLoading, setIsLoading] = useState(true);
const [enabledPagination, setEnabledPagination] = useState(false);
useEffect(() => {
const initialize = async () => {
const data = await fetchFirstPageData(itemsPerPage);
if (data) {
initCurrentViewItems(data.items);
updateTotalPages(data.totalCount, itemsPerPage);
}
setIsLoading(false);
};
const fetchAllData = async () => {
const items = await fetchAllPageData();
setAllItems(sorter(items));
setEnabledPagination(true);
};
initialize();
fetchAllData();
}, []);
const handleSelectOrderBy = () => {
if (!enabledPagination) {
// 初回描画時に 全データ取得が終わっていない状態でこの関数が呼ばれ、空になるため終わるまでは何もしない
return;
}
setAllItems(sorter(getAllItems()));
updateCurrentViewItems(getAllItems(), itemsPerPage, activePage);
};
const handleSelectActivePage = () => {
if (!enabledPagination) {
// 初回描画時に 全データ取得が終わっていない状態でこの関数が呼ばれ、空になるため終わるまでは何もしない
return;
}
updateCurrentViewItems(getAllItems(), itemsPerPage, activePage);
};
const handleSelectItemsPerPage = () => {
if (!enabledPagination) {
// 初回描画時に 全データ取得が終わっていない状態でこの関数が呼ばれ、空になるため終わるまでは何もしない
return;
}
const firstPage = 1;
updateTotalPages(getAllItems().length, itemsPerPage);
setActivePage(firstPage);
updateCurrentViewItems(getAllItems(), itemsPerPage, firstPage);
};
if (isLoading) {
// Todo
return <div>Loading...</div>;
}
if (currentViewItems == null || currentViewItems.length === 0) {
// Todo
return <div>Empty</div>;
}
return (
<>
<Group position="apart" sx={{ margin: "0 1rem" }}>
<OrderSelectBox
handleSelectOrder={handleSelectOrderBy}
sorterReducerSet={[sorter, dispatch]}
></OrderSelectBox>
<ItemsPerPageSelection
enabled={enabledPagination}
handleSelectItemsPerPage={handleSelectItemsPerPage}
stateSet={[itemsPerPage, setItemsPerPage]}
/>
</Group>
<ScrollArea h={window.innerHeight - 135} sx={{ padding: "0.5rem" }}>
<Checkbox.Group value={selectedItems} onChange={setSelectedItems}>
{children}
</Checkbox.Group>
</ScrollArea>
<Pagination
totalPages={totalPages}
enabled={enabledPagination}
handleSelectActivePage={handleSelectActivePage}
activePageStateSet={[activePage, setActivePage]}
/>
</>
);
};
- order-select-box コンポーネント
import { Text, Flex, NativeSelect, SegmentedControl } from "@mantine/core";
import { useEffect, useState } from "react";
import { Directions, Orders, Sorter } from "./types";
import { useSorterReducer } from "./hooks/useSorterReducer";
const defaultOrderByValues = [
{ label: "name", value: "NAME" },
{ label: "created time", value: "CREATED_AT" },
{ label: "updated time", value: "UPDATED_AT" },
];
const defaultDirectionValues = [
{ label: "Asc", value: "ASC" },
{ label: "Desc", value: "DESC" },
];
type Props = {
handleSelectOrder: (itemsSorter: Sorter) => void;
sorterReducerSet?: ReturnType<typeof useSorterReducer>;
};
export const OrderSelectBox = ({
handleSelectOrder,
sorterReducerSet: [sorter, dispatch] = useSorterReducer(),
}: Props) => {
const [order, setOrder] = useState<string>("NAME");
const [direction, setDirection] = useState<string>("ASC");
useEffect(() => {
handleSelectOrder(sorter);
}, [order, direction]);
return (
<Flex align="center" sx={{ "&>*": { margin: "0 0.25rem" } }}>
<Text size="sm">order by:</Text>
<NativeSelect
value={order}
onChange={(event) => {
const value = event.currentTarget.value;
setOrder(value);
dispatch({
order: value as Orders,
direction: direction as Directions,
});
}}
data={defaultOrderByValues}
/>
<SegmentedControl
value={direction}
onChange={(value: string) => {
setDirection(value);
dispatch({
order: order as Orders,
direction: value as Directions,
});
}}
data={defaultDirectionValues}
/>
</Flex>
);
};
- items-per-page-select-box コンポーネント
import { Flex, SegmentedControl, Text } from "@mantine/core";
import { useEffect } from "react";
import { useItemsPerPage } from "./hooks/useItemsPerPage";
const defaultItemsPerPageChoices = [
{ label: "10", value: "10" },
{ label: "20", value: "20" },
{ label: "30", value: "30" },
{ label: "50", value: "50" },
{ label: "100", value: "100" },
];
type Props = {
itemsPerPageChoices?: typeof defaultItemsPerPageChoices;
enabled: boolean;
handleSelectItemsPerPage: () => void;
stateSet?: ReturnType<typeof useItemsPerPage>;
};
export const ItemsPerPageSelection = ({
itemsPerPageChoices,
enabled,
handleSelectItemsPerPage: handleChangeItemsPerPage,
stateSet: [itemsPerPage, setItemsPerPage] = useItemsPerPage(20),
}: Props) => {
useEffect(() => handleChangeItemsPerPage(), [itemsPerPage]);
return (
<Flex align="center" sx={{ "&>*": { margin: "0 0.2rem" } }}>
<SegmentedControl
value={itemsPerPage.toString()}
onChange={setItemsPerPage}
data={itemsPerPageChoices ?? defaultItemsPerPageChoices}
disabled={!enabled}
/>
<Text fz="sm">: Items per Page</Text>
</Flex>
);
};
- pagination コンポーネント
import { Pagination as MantinePagenation } from "@mantine/core";
import { useActivePage } from "./hooks/useActivePage";
type Props = {
enabled: boolean;
totalPages: number;
activePageStateSet?: ReturnType<typeof useActivePage>;
};
export const Pagination = ({
enabled,
totalPages = 1,
activePageStateSet: [activePage, setActivePage] = useActivePage(),
}: Props) => {
return (
<MantinePagenation
sx={{
padding: "0.5rem 0.25rem",
}}
total={totalPages}
position="center"
value={activePage}
onChange={setActivePage}
disabled={!enabled}
/>
);
};
分割したものの、以下の違和感を感じている
- 分割した部品の単一性のために、ロジックを親コンポーネントにあたる checkable-line-boxes-pagination コンポーネントに定義して渡している。
- currentViewItems (現在のページに表示するリポジトリを保持するステート) を checkable-line-boxes-pagination コンポーネントで管理したいが、repository-list コンポーネントで、管理せざるを得なくなっている。
After 2
フロントエンドのデザインパターン を参考に、以下を適用した
- レンダープロップパターン
- これにより、currentViewItems を checkable-line-boxes-pagination コンポーネント に持たせる
- 複合パターン(&プロバイダーパターン)
コンテナ・プレゼンテーションパターン
checkable-line-boxes-viewer (旧:checkable-line-boxes-pagination)
import { Group } from "@mantine/core";
import { CheckableLineData } from "../../components/checkable-line-box/checkable-line-box";
import { ReactNode } from "react";
import { useSorterReducer } from "../../components/order-select-box";
import { useCheckableLineItemsRef } from "./hooks/useCheckableLineItemsRef";
import { CheckableLineBoxesContainer } from "./components/checkable-line-boxes-container";
type CheckableLineBoxesViewerProps = {
selectedItems: string[];
setSelectedItems: (items: string[]) => void;
fetchFirstPageData: (
itemPerPage: number
) => Promise<{ items: CheckableLineData[]; totalCount: number } | undefined>;
fetchAllPageData: () => Promise<CheckableLineData[]>;
sorterReducerSet?: ReturnType<typeof useSorterReducer>;
render: (
currentViewItems: CheckableLineData[],
itemsRef: ReturnType<typeof useCheckableLineItemsRef>
) => ReactNode;
};
export const CheckableLineBoxesViewer = ({
selectedItems,
setSelectedItems,
fetchFirstPageData,
fetchAllPageData,
sorterReducerSet: [itemsSorter, dispatchSortOptions] = useSorterReducer(),
render,
}: CheckableLineBoxesViewerProps) => {
return (
<CheckableLineBoxesContainer
fetchFirstPageData={fetchFirstPageData}
fetchAllPageData={fetchAllPageData}
itemsSorter={itemsSorter}
>
<Group position="apart" sx={{ margin: "0 1rem" }}>
<CheckableLineBoxesContainer.OrderBy
dispatchSortOptions={dispatchSortOptions}
/>
<CheckableLineBoxesContainer.ItemsPerPage />
</Group>
<CheckableLineBoxesContainer.Group
selectedItems={selectedItems}
setSelectedItems={setSelectedItems}
render={render}
/>
<CheckableLineBoxesContainer.PaginationBox />
</CheckableLineBoxesContainer>
);
};
- checkable-line-boxes-container
import { ReactNode, useEffect, useState } from "react";
import { CheckableLineData } from "src/components/checkable-line-box";
import { useSorterReducer } from "src/components/order-select-box";
import { useCheckableLineItemsRef } from "../hooks/useCheckableLineItemsRef";
import { useCurrentViewItems } from "../hooks/useCurrentViewItems";
import { useItemsPerPage } from "src/components/items-per-page-select-box";
import { useTotalPages } from "../hooks/useTotalPages";
import { CheckableLineBoxesProvider } from "../checkable-line-boxes.context";
import { ItemsPerPage } from "./items-per-page";
import { OrderBy } from "./order-by";
import { Group } from "./group";
import { PaginationBox } from "./pagination-box";
type CheckableLineBoxesContainerProps = {
fetchFirstPageData: (
itemPerPage: number
) => Promise<{ items: CheckableLineData[]; totalCount: number } | undefined>;
fetchAllPageData: () => Promise<CheckableLineData[]>;
itemsSorter: ReturnType<typeof useSorterReducer>[0];
children: ReactNode;
};
export const CheckableLineBoxesContainer = ({
fetchFirstPageData,
fetchAllPageData,
itemsSorter,
children,
}: CheckableLineBoxesContainerProps) => {
const itemsRef = useCheckableLineItemsRef(itemsSorter);
const [currentViewItems, initCurrentViewItems, updateCurrentViewItems] =
useCurrentViewItems();
const [activePage, setActivePage] = useState(1);
const [totalPages, updateTotalPages] = useTotalPages();
const [itemsPerPage, setItemsPerPage] = useItemsPerPage(20);
const [isLoading, setIsLoading] = useState(true);
const [enabledPagination, setEnabledPagination] = useState(false);
useEffect(() => {
const initialize = async () => {
const data = await fetchFirstPageData(itemsPerPage);
if (data) {
initCurrentViewItems(data.items);
updateTotalPages(data.totalCount, itemsPerPage);
}
setIsLoading(false);
};
const fetchAllData = async () => {
const items = await fetchAllPageData();
itemsRef.allItems = items;
itemsRef.sort();
setEnabledPagination(true);
};
initialize();
fetchAllData();
}, []);
return (
<CheckableLineBoxesProvider
value={{
itemsRef,
currentViewItems,
updateCurrentViewItems,
activePage,
setActivePage,
totalPages,
updateTotalPages,
itemsPerPage,
setItemsPerPage,
isLoading,
enabledPagination,
}}
>
{children}
</CheckableLineBoxesProvider>
);
};
CheckableLineBoxesContainer.ItemsPerPage = ItemsPerPage;
CheckableLineBoxesContainer.OrderBy = OrderBy;
CheckableLineBoxesContainer.Group = Group;
CheckableLineBoxesContainer.PaginationBox = PaginationBox;
- checkable-line-boxes-context
import { useItemsPerPage } from "src/components/items-per-page-selection";
import { useCheckableLineItemsRef } from "./hooks/useCheckableLineItemsRef";
import { useCurrentViewItems } from "./hooks/useCurrentViewItems";
import { useTotalPages } from "./hooks/useTotalPages";
import { createContext, useContext } from "react";
type ContextValues = {
itemsRef: ReturnType<typeof useCheckableLineItemsRef>;
currentViewItems: ReturnType<typeof useCurrentViewItems>[0];
updateCurrentViewItems: ReturnType<typeof useCurrentViewItems>[2];
activePage: number;
setActivePage: (page: number) => void;
totalPages: ReturnType<typeof useTotalPages>[0];
updateTotalPages: ReturnType<typeof useTotalPages>[1];
itemsPerPage: ReturnType<typeof useItemsPerPage>[0];
setItemsPerPage: ReturnType<typeof useItemsPerPage>[1];
isLoading: boolean;
enabledPagination: boolean;
};
const CheckableLineBoxesContext = createContext<any>({});
export const CheckableLineBoxesProvider = CheckableLineBoxesContext.Provider;
export const useCheckableLineBoxesContext = () =>
useContext<ContextValues>(CheckableLineBoxesContext);
- items-per-page
import { useEffect } from "react";
import { useCheckableLineBoxesContext } from "../checkable-line-boxes.context";
import { ItemsPerPageSelectBox } from "src/components/items-per-page-select-box";
export const ItemsPerPage = () => {
const {
itemsRef,
updateCurrentViewItems,
setActivePage,
updateTotalPages,
itemsPerPage,
setItemsPerPage,
enabledPagination,
} = useCheckableLineBoxesContext();
useEffect(() => {
if (!enabledPagination) {
// 初回描画時に 全データ取得が終わっていない状態でこの関数が呼ばれ、空になるため終わるまでは何もしない
return;
}
const firstPage = 1;
updateTotalPages(itemsRef.allItems.length, itemsPerPage);
setActivePage(firstPage);
updateCurrentViewItems(itemsRef.allItems, itemsPerPage, firstPage);
}, [itemsPerPage]);
return (
<ItemsPerPageSelectBox
enabled={enabledPagination}
stateSet={[itemsPerPage, setItemsPerPage]}
/>
);
};
- order-by
import { useEffect } from "react";
import {
OrderSelectBox,
useSortOptions,
useSorterReducer,
} from "src/components/order-select-box";
import { useCheckableLineBoxesContext } from "../checkable-line-boxes.context";
export const OrderBy = ({
dispatchSortOptions,
}: {
dispatchSortOptions: ReturnType<typeof useSorterReducer>[1];
}) => {
const {
itemsRef,
updateCurrentViewItems,
activePage,
itemsPerPage,
enabledPagination,
} = useCheckableLineBoxesContext();
const [sortOptions, setSortOptions] = useSortOptions();
useEffect(() => {
if (!enabledPagination) {
// 初回描画時に 全データ取得が終わっていない状態でこの関数が呼ばれ、空になるため終わるまでは何もしない
return;
}
itemsRef.sort();
updateCurrentViewItems(itemsRef.allItems, itemsPerPage, activePage);
}, [sortOptions.order, sortOptions.direction]);
return (
<OrderSelectBox
enabled={enabledPagination}
dispatchSortOptions={dispatchSortOptions}
sortOptionsStateSet={[sortOptions, setSortOptions]}
></OrderSelectBox>
);
};
- group
import { ReactNode } from "react";
import { CheckableLineData } from "src/components/checkable-line-box";
import { useCheckableLineItemsRef } from "../hooks/useCheckableLineItemsRef";
import { useCheckableLineBoxesContext } from "../checkable-line-boxes.context";
import { Checkbox, ScrollArea } from "@mantine/core";
export const Group = ({
selectedItems,
setSelectedItems,
render,
}: {
selectedItems: string[];
setSelectedItems: (items: string[]) => void;
render: (
currentViewItems: CheckableLineData[],
itemsRef: ReturnType<typeof useCheckableLineItemsRef>
) => ReactNode;
}) => {
const { itemsRef, currentViewItems } = useCheckableLineBoxesContext();
return (
<ScrollArea h={window.innerHeight - 180} sx={{ padding: "0.5rem" }}>
<Checkbox.Group value={selectedItems} onChange={setSelectedItems}>
{render(currentViewItems, itemsRef)}
</Checkbox.Group>
</ScrollArea>
);
};
- pagination-box
import { useEffect } from "react";
import { useCheckableLineBoxesContext } from "../checkable-line-boxes.context";
import { Pagination } from "src/components/pagination";
export const PaginationBox = () => {
const {
itemsRef,
itemsPerPage,
totalPages,
activePage,
setActivePage,
updateCurrentViewItems,
enabledPagination,
} = useCheckableLineBoxesContext();
useEffect(() => {
if (!enabledPagination) {
// 初回描画時に 全データ取得が終わっていない状態でこの関数が呼ばれ、空になるため終わるまでは何もしない
return;
}
updateCurrentViewItems(itemsRef.allItems, itemsPerPage, activePage);
}, [activePage]);
return (
<Pagination
totalPages={totalPages}
enabled={enabledPagination}
activePageStateSet={[activePage, setActivePage]}
/>
);
};
まだ荒はあるが、一旦ここまでとする
最後に
ある程度納得いく形にはできた。ただ、やりすぎか、適切かどうか判断が付かない。
参考になりそうなフレームワーク等を見つけて、どう考えて分割するのが良いか学習が必要そう。
以上
gPRC: Protocol Buffers スタイル規約 & API ベストプラクティスまとめ
- gPRC: Protocol Buffers スタイル規約 & API ベストプラクティスまとめ
- ファイル & パッケージ構成
- Message
- Enum
- Service
- Proto ベストプラクティス
- API ベストプラクティス
- フィールドとメッセージを正確かつ簡潔に文書化する
- Wire (≒API?)と Storage でメッセージを使い分ける
- Mutations (更新 API) の場合、データの完全なリプレイスではなく、部分的な更新または追加のみの更新をサポートする
- トップレベルのリクエストまたはレスポンスの proto にプリミティブ型(基本のデータ型)を含めない
- (現在は 2 つの状態を持つが)後でさらに多くの状態を持つ可能性があるものには boolean を使用しない
- ID に整数フィールドをほとんど使用しない
- Web-Safe Encoding Binary Proto Serialization で不透明なデータを文字列でエンコードする
- クライアントが構築または解析すると予想される文字列内のデータをエンコードしない
- クライアントが使用できない可能性のあるフィールドを含めない
- 継続トークンなしでページ区切り API を定義しない
- 関連するフィールドを新しいメッセージにまとめる。親和性の高いフィールドだけをネストする
- 読み取り要求にフィールド読み取りマスクを含める
- 一貫した読み取りを可能にするバージョンフィールドを含める
- 同じデータ型を返す RPC には一貫したリクエストオプションを使用する
- Batch/Multi-phase リクエスト
- 小さなデータを返す/操作するメソッドを作成し、クライアントが複数の要求をまとめて UI を構成することを期待する
- モバイルやウェブで連続したラウンドトリップが必要な場合、1 回限りの RPC を作成する
- Proto Maps を使用する
- 冪等性を優先
- サービス名はグローバル(ネットワーク上)でユニークなものにする
- すべての RPC で(許可制の)期限を指定して強制する
- リクエストサイズとレスポンスサイズの境界
- ステータスコードの伝搬は慎重に
- Reapeated フィールドの Tips
- パフォーマンスの最適化
- ref:
gPRC: Protocol Buffers スタイル規約 & API ベストプラクティスまとめ
設計する上で、公式ドキュメント(英語)を翻訳機で訳してまとめただけ。
ファイル & パッケージ構成
- 全てのファイルにパッケージを定義
- 同じパッケージのファイルは全てパッケージ名と一致する同じディレクトリに入れる
- パッケージの最後のコンポーネントは バージョンにする
- パッケージ名の形式:lower_snake_case
- ファイル名の形式:lower_snake_case.proto
- 繰り返しフィールドに複数形の名前を使用
.
└── proto
├── buf.yaml
└── foo
└── bar
├── bat
│ └── v1
│ └── bat.proto // package foo.bar.bat.v1
└── baz
└── v1
├── baz.proto // package foo.bar.baz.v1
└── baz_service.proto // package foo.bar.baz.v1
- 同じパッケージ内の全 proto ファイルで、以下オプションは揃える(値と有無)
csharp_namespacego_packagejava_multiple_filesjava_packagephp_namespaceruby_packageswift_prefix
// foo_one.proto syntax = "proto3"; package foo.v1; option go_package = "foov1"; option java_multiple_files = true; option java_package = "com.foo.v1";
// foo_two.proto syntax = "proto3"; package foo.v1; option go_package = "foov1"; option java_multiple_files = true; option java_package = "com.foo.v1";
Message
- Message 名は PascalCase
- フィールド名は lower_snake_case
syntax = "proto3"; message SearchRequest { string query = 1; int32 page_number = 2; int32 result_per_page = 3; oneof test_oneof { // セットで扱うものをまとめられる string name = 4; SubMessage sub_message = 5; } optional string song_name = 6; repeated string keys = 7; map<string, Project> projects = 8; // map に repeated は使えない reserved 2, 15, 9 to 11; // reserved: 予約済みフィールド reserved "foo", "bar"; // 主に削除済みのフィールドに使用 } message Project { ... }
Field
種類:
- oneof
- optional
- repeated
- map
- reserved
スカラー値の型:
- double/float
- int32/int64
- uint32/uint64:正の値
- sint32/sint64:int32/int64 より効率的に負の数をエンコードできる
- fixed32:常に 4bytes。228 を超える場合は uint32 より効率的にエンコード
- fixed64:常に 8bytes。256 を超える場合は uint64 より効率的にエンコード
- sfixed32:常に 4bytes。
- sfixed64:常に 8bytes。
- bool
- string
- bytes: 232 以下の任意のバイトシーケンス
ルール:
- 1 ~ 15 のフィールド番号は、(1byte のため)非常に頻繁に使用するフィールド用に予約する
- たまにしか使わないフィールドは、16 ~ 2047 (2byte) を使い、頻繁に使用するフィールドとして予約できる余地を残しておく必要がる
- フィールド番号の最大は 229 - 1 (= 536,870,911)
- 19000 から 19999 までの数字は ProtocolBuffers の実装のために予約されているため使用不可(使用した場合はコンパイラから警告)
Nested Type
できるが、ネストされた Message の使用は避ける
message SearchResponse { message Result { string url = 1; string title = 2; repeated string snippets = 3; } repeated Result results = 1; }
他のメッセージで利用する場合
message SomeOtherMessage { SearchResponse.Result result = 1; }
Any
- google/protobuf/any.proto をインポートする必要がある
- Any には、任意のシリアル化されたメッセージがバイトとして含まれ、そのメッセージのタイプのグローバル一意識別子として機能し、解決される URL が含まれる
- 言語の実装で、Any 値を型安全な方法でパックおよびアンパックするランタイムライブラリヘルパーがサポート
import "google/protobuf/any.proto"; message ErrorStatus { string message = 1; repeated google.protobuf.Any details = 2; }
Enum
- Enum には allow_alias オプションを設定しない
- Enum 名は PascalCase
- Enum 値の名前は UPPER_SNAKE_CASE
- Enum 値の名前の先頭には、Enum 名の UPPER_SNAKE_CASE を付ける
- すべての Enum の 0 の値の末尾には_UNSPECIFIED を付ける
enum Corpus { CORPUS_UNSPECIFIED = 0; CORPUS_UNIVERSAL = 1; CORPUS_WEB = 2; CORPUS_IMAGES = 3; CORPUS_LOCAL = 4; CORPUS_NEWS = 5; CORPUS_PRODUCTS = 6; CORPUS_VIDEO = 7; } message SearchRequest { string query = 1; int32 page_number = 2; int32 result_per_page = 3; Corpus corpus = 4; }
allow_alias:同じフィールド番号を許容
enum EnumAllowingAlias { option allow_alias = true; EAA_UNSPECIFIED = 0; EAA_STARTED = 1; EAA_RUNNING = 1; EAA_FINISHED = 2; } enum EnumNotAllowingAlias { ENAA_UNSPECIFIED = 0; ENAA_STARTED = 1; // ENAA_RUNNING = 1; // コメントを外すと警告メッセージ表示 ENAA_FINISHED = 2; }
※列挙子の数に言語固有の制限がある場合がある (1 つの言語で 1000 以下)
Service
- Service 名は PascalCase
- Service 名の末尾には Service を付ける
- RPC 名は PascalCase にする
- すべての RPC 要求および応答メッセージは、Protobuf スキーマ全体で一意である必要がある
- すべての RPC 要求および応答メッセージには、以下の命名にする
- < MethodName > Request
- < MethodName > Response
- < ServiceName >< MethodName > Request
- < ServiceName >< MethodName > Response
service FooService { rpc GetSomething(GetSomethingRequest) returns (GetSomethingResponse); rpc ListSomething(ListSomethingRequest) returns (ListSomethingResponse); }
※(議論の余地はあるが)RPC のストリーミングを避けることを推奨する。(これらは確かに非常に価値のある特定のユースケースを持っていますが、全 体としては多くの問題を引き起こし、RPC フレームワークのロジックをスタックに押し上げるため、通常はより信頼性の高いアーキテクチャの開発を妨げる)
Proto ベストプラクティス
- タグ番号は再利用しない
- フィールドのタイプは変更しない
- 必須フィールドを追加しない
- フィールドが多い(数百)メッセージは作らない
- Enum に 宣言の最初の値としてデフォルトの Unspecified Value(XXX_UNSPECIFIED)を含める
- デフォルト値が存在しない場合は最初に宣言された値が返されるため
- enum は最初の値がで 0 あることを要求するため値は 0 にする
- Well-Known Types と Common Types を使う
- 以下の共通型、共有型を埋め込むことを強く推奨
- Well-Known Types
- duration:符号付き固定長の時間スパン (例:42s)
- timestamp:例 2017-01-15T01:30:15.01Z
- field_mask:指定のフィールドのみ取るためのもの
- Common Types
- Well-Known Types
- 完全に適した共通型がすでに存在する場合、コード内で
int32 timestamp_seconds_since_epochやint64 timeout_millisを使用しない
- 以下の共通型、共有型を埋め込むことを強く推奨
- 広く使用されることを期待する Message Type や Enum は別のファイルに定義し、誰でも簡単に使えるようにする
- 削除されたフィールドのタグ番号は予約(reserved)して、後で誤って再使用しないようにする
- フィールドのデフォルト値は変更しない(proto3 ではデフォルト値を設定する機能は削除)
- rotated から Scalar に移行しない。クラッシュはしないがデータ失われる(逆は大丈夫)
- 生成されたコードのスタイルガイドに従う
- テキスト形式のメッセージをやり取りに使用しない(テキスト形式は、人による編集とデバッグにのみ使用)
- ビルド間でのシリアライゼーションの安定性に決して依存しない
- proto シリアライズの安定性は、バイナリ間でも、同じバイナリのビルド間でも保証されない(ビルドする度中身が変わる)ため、キャッシュキーの構築等で依存してはいけない
ref: https://protobuf.dev/programming-guides/dos-donts/
API ベストプラクティス
公式ドキュメントの記載は、長期的でバグのない進化を優先するためにトレードオフを行った上での提案 ref: https://protobuf.dev/programming-guides/api/
フィールドとメッセージを正確かつ簡潔に文書化する
- 各フィールドの制約、期待、解釈をできるだけ短い言葉で文書化
- 時間経過とともに長くなるかもしれないが、全体的に見て簡潔にすることを目指す
Wire (≒API?)と Storage でメッセージを使い分ける
- クライアントに公開するトップレベルの proto が、ディスクに保存する proto を同じにしない
- クライアントに影響を与えることなく、保存形式を変更できる自由度が必要
- コードをレイヤー化し、モジュールが client protos、storage protos、translation のいずれかを処理するように分ける
- 例外
Mutations (更新 API) の場合、データの完全なリプレイスではなく、部分的な更新または追加のみの更新をサポートする
- (1) Update Field-mask を使用する。
- クライアントが変更するフィールドを渡し、それらのフィールドだけを更新要求に含める。
- サーバは他のフィールドをそのままにし、マスクで指定されたフィールドのみを更新する。
- 一般的に、マスクの構造は応答 proto の構造を反映する必要がある(= Foo に Bar が含まれている場合、FooMask には BarMask を含める)
- (2) 個々のピースを変化させる より狭い Mutations API を公開する
- 例:UpdateEmployeeRequest の代わりに、PromoteEmployeeRequest、SetEmployeePayRequest、TransferEmployeeRequest など(用途特化?)
- カスタム更新方法は、非常に柔軟な更新方法よりも監視、監査、およびセキュリティが容易かつ実装や呼び出しも簡単。ただし、その数が多いと API の認知負荷が増大する可能性があるため注意。
トップレベルのリクエストまたはレスポンスの proto にプリミティブ型(基本のデータ型)を含めない
- トップレベルの proto は、ほとんどの場合、独立して成長できる他のメッセージのコンテナである必要がある
- 必要なプリミティブ型が 1 つだけの場合でも、メッセージにラップすることで、その型を拡張し、類似した値を返す他のメソッド間で型を共有するた めの明確なパスが得られる
message MultiplicationResponse { // 悪い例:複素数を返す必要があり、同じ複数フィールド型を返すレスポンスが必要な場合に // どちらにもプリミティブ型のフィールドを追加するのは避けたいはず optional double result; // 良い例:他のメソッドはこのタイプを共有でき、成長可能 // サービスは、新しい機能 (単位、信頼区間など) を容易に追加可能。 optional NumericResult result; } message NumericResult { optional double real_value; optional double complex_value; optional UnitType units; }
トップレベルプリミティブの例外
- プロトをエンコードするが、サーバー上でのみ構築および解析される不透明な文字列 (またはバイト)
- 継続トークン、バージョン情報トークン、ID は、文字列が実際に構造化プロトのエンコードである場合、すべて文字列として返すことができる。
(現在は 2 つの状態を持つが)後でさらに多くの状態を持つ可能性があるものには boolean を使用しない
フィールドに boolean を使用する場合は、フィールドが(将来的にも)実際に 2 つの可能な状態だけになるかを確認する。
message GooglePlusPost { // 悪い例:この投稿を2つのカラムにまたがってレンダリングするかどうか optional bool big_post; // 良い例:この投稿を表示するクライアントのためのレンダリングヒント // クライアントは、この投稿をどの程度目立つように表示するかを決定するために、これを使用。 // ない場合は、デフォルトのレンダリングを想定。 optional LayoutConfig layout_config; } message Photo { // 悪い例: GIFかどうか optional bool gif; // 良い例: 写真のファイル形式(例:GIF、WebP、PNG)。 optional PhotoType type; }
概念を混同する enum に state を追加することには、注意が必要
- もし state が enum に新しい次元を導入する場合や、複数のアプリケーションの動作を意味する場合、ほぼ間違いなく別のフィールドが必要
ID に整数フィールドをほとんど使用しない
- オブジェクトの識別子として int 64 を使いたくなるが、文字列を選択する
- 必要に応じて ID スペースを変更し、衝突の可能性を減らせる(264 は今では大きくはない)
- 構造化識別子を文字列としてエンコードすることで、クライアントに不透明な Blob として扱うように促すことも可能。
message GetFooRequest { // Which Foo to fetch. optional string foo_id; } // websafe-base64-encoded & シリアライズして、 GetFooRequest.foo_idフィールドにセット message InternalFooRef { // Only one of these two is set. Foos that have already been // migrated use the spanner_foo_id and Foos still living in // Caribou Storage Server have a classic_foo_id. optional bytes spanner_foo_id; optional int64 classic_foo_id; }
Web-Safe Encoding Binary Proto Serialization で不透明なデータを文字列でエンコードする
- クライアントから見えるフィールドの不透明なデータ(継続トークン、シリアル化された ID、バージョン情報など)をエンコードする場合は、クライア ントが不透明な Blob として扱う必要があることを文書化する。
- これらのフィールドには、必ずバイナリ形式のプロトシリアライゼーションを使用し、テキスト形式や独自の工夫をしない。不透明なフィールドにエンコードされたデータを拡張する必要がある場合、まだ使用していなければ、プロトコルバッファのシリアル化を再発明することになるため。
- 不透明なフィールドに入るフィールドを保持する内部 proto を定義し (フィールドが 1 つだけ必要な場合でも) 、この内部 proto をバイトにシリア ル化し、その結果を web-safe base-64 で文字列フィールドにエンコードします。
- プロトシリアライゼーションを使用するまれな例外:非常に時折、慎重に構築された代替形式からのコンパクトさの勝利は価値がある。
クライアントが構築または解析すると予想される文字列内のデータをエンコードしない
ネットワーク上では効率が悪く、proto の利用者にとっては手間がかかり、ドキュメントを読んでいる人にとっては混乱を招く。
クライアントはエンコーディングについても気にする必要がある
- リストはコンマ区切りか?
- この信頼できないデータは正しくエスケープされているか?
- 数字は 10 を底としているか?
クライアントに実際のメッセージやプリミティブタイプを送信させる方がよい。その方が、ネットワーク全体でよりコンパクトになり、クライアントにとってより明確になる
- サービスで複数言語のクライアントを取得した場合に特に悪化する。各自が適切なパーサーやビルダーを選択しなければならなくなり、最悪の場合それを書かなければならなくなる。
- より一般的には、正しいプリミティブ型を選択する。
- 『Protocol Buffer Language Guide』の 「Scalar Value Types」 の表を参照
フロントエンド proto で HTML を返す
JavaScript クライアントには、API のフィールドで HTML や JSON を返さない。 (返すと API を特定の UI に結びつけるため良くない)
具体的な 3 つの危険性:
- 「スクラッピー」 な非 Web クライアントは、HTML や JSON を解析して、フォーマットを変更した場合の脆弱性や、解析が悪い場合の脆弱性につなが るデータを取得することになる
- Web クライアントは、その HTML がサニタイズされずに返された場合、XSS エクスプロイトに対して脆弱になる。
- 返されるタグとクラスは、特定のスタイルシートと DOM 構造を想定しているが、リリースごとに構造が変化し、JavaScript クライアントがサーバーより古くなると、サーバーが返す HTML が古いクライアントで正しくレンダリングされなくなるバージョンスキューの問題が発生するリスクがある。(リリース頻度の高いプロジェクトでは、これはエッジケースではない)
最初のページロード以外では、通常データを返しクライアント側のテンプレートを使用してクライアント上で HTML を構築する方がよい
クライアントが使用できない可能性のあるフィールドを含めない
クライアントに公開する API には、
- システムとの対話方法を記述するためだけのもののみ含める
- その中に他の何かを含めると、それを理解しようとする人に認知的オーバーヘッドが加わる
以前は応答プロトコルでデバッグデータを返すのが一般的でしたが、今はより良い方法がある
- RPC レスポンス拡張(「サイドチャネル」とも呼ばれる)により、あるプロトでクライアントインタフェースを記述し、別のプロトでデバッグサーフェスを記述することができる
- (同様に応答 proto で実験名を返すのは、以前はログ記録の利便性があり、不文律の契約では、クライアントは後続のアクションでそれらの実験を送 り返していた)同じことを実現する方法は、分析パイプラインでログの結合を行うこと。
1つの例外:
- 継続的なリアルタイム分析が必要で、マシンの予算が少ない場合は、ログ結合の実行は困難な場合がある。
- コストが決定要因である場合は、ログデータを事前に非正規化することが有効な場合がある。
- ログデータのラウンドトリップが必要な場合は、不透明な Blob としてクライアントに送信し、要求フィールドと応答フィールドを文書化する。
Caution:
- 要求のたびに隠しデータを返したり往復したりするのは、サービスを利用するための本当のコストを隠していることになり、良くない。
継続トークンなしでページ区切り API を定義しない
message FooQuery { // Bad:最初のクエリと2番目のクエリの間でデータが変更された場合、 // これらの各戦略によって結果を見逃す可能性があります。 // 最終的に一貫性のある世界(つまり、Bigtableにバックアップされたストレージ)では、 // 新しいデータの後に古いデータが表示されることは珍しくない。 // また、オフセットベースとページベースのアプローチはすべてソート順を前提としているため、 // ある程度の柔軟性が失われる。 optional int64 max_timestamp_ms; optional int32 result_offset; optional int32 page_number; optional int32 page_size; // Good: 柔軟性がある。これを FooQueryResponse で返し、 // クライアントが次のクエリでそれを返すようにする。 optional string next_page_token; }
- シリアル化する内部プロトに裏打ちされた不透明な継続トークン (next_page_token) を使用してから、WebSafeBase64Escape (C++) または BaseEncoding.base64Url().encode (Java) を使用すること。
- その内部プロトは多くの分野を含む可能性がある。重要なのは、それが柔軟性をもたらし、選択すれば、クライアントに安定した結果をもたらすということ。
message InternalPaginationToken { // これまでに確認されたIDを追跡する // これにより、継続トークンが大きくなる代わりに、完璧な想起が可能になる // --特に、ユーザがページを戻したとき repeated FooRef seen_ids; // seen_idsストラテジーに似ているが、seen_idsをBloomフィルタにかけることで // バイトを節約し、精度を犠牲にする optional bytes bloom_filter; // 合理的な最初のカットであり、より長く機能する可能性がある. // 継続トークンに埋め込んでおけば、後でクライアントに影響を与えることなく変更できる optional int64 max_timestamp_ms; }
関連するフィールドを新しいメッセージにまとめる。親和性の高いフィールドだけをネストする
message Foo { // Bad: optional int price; optional CurrencyType currency; // Better: Fooの価格と通貨をカプセル化 optional CurrencyAmount price; }
後で関連するフィールドを持つ可能性がある場合、これを回避するために事前に入れる。
message Foo { // DEPRECATED! Use currency_amount. optional int price [deprecated = true]; // The price and currency of this Foo. optional google.type.Money currency_amount; }
疎結合はシステムを開発する際のベストプラクティスだが、.proto ファイルを設計する際には必ずしもそのプラクティスが適用されない場合がある。
message Photo { // Bad: PhotoMetadataはPhotoの範囲外で再利用される可能性が高いので、 // 入れ子にせず、アクセスしやすくしておくといいかもしれませんね。 message PhotoMetadata { optional int32 width = 1; optional int32 height = 2; } optional PhotoMetadata metadata = 1; } message FooConfiguration { // Good: FooConfiguration.RuleをFooConfigurationのスコープ外で再利用すると、 // 無関係なコンポーネントと密接に結合する可能性が高いため、ネスティングして再利用を防ぐ。 message Rule { optional float multiplier = 1; } repeated Rule rules = 1; }
読み取り要求にフィールド読み取りマスクを含める
読み取りマスク
- クライアント側に明確な期待値を設定し、返すデータの量を制御し、バックエンドがクライアントが必要とするデータのみを取得できるようにする。
- すべてのフィールドが true に設定された暗黙の読み取りマスクがあるかのように要求を処理する(proto が大きくなるにつれてコストが大きくなる)
- 暗黙的な (宣言されていない) 読み取りマスク は Bad
これは、プロトコールが大きくなるにつれてコストがかかる可能性があります。
// Recommended: use google.protobuf.FieldMask // Alternative one: message FooReadMask { optional bool return_field1; optional bool return_field2; } // Alternative two: message BarReadMask { // 返すフィールドのタグ番号。 repeated int32 fields_to_return; }
一貫した読み取りを可能にするバージョンフィールドを含める
(分散システムの話?)
クライアントが書き込みを行った後に同じオブジェクトを読み込む場合、書き込んだ内容が戻ってくることを期待するが、その期待値が基となるストレージシステムにとって妥当でない場合もある。
サーバーはローカルの値を読み、ローカルの version_info が、期待される version_info より小さい場合、リモートレプリカから読み取って最新の値を見つける。
version_info は文字列としてエンコードされたプロトで、変異が起こったデータセンターとコミットされたタイムスタンプを含む。(エンコードは「Web-Safe Encoding Binary Proto Serialization で不透明なデータを文字列でエンコードする」参照)
同じデータ型を返す RPC には一貫したリクエストオプションを使用する
要求オプションを保持する単一の個別のメッセージを作成し、それを最上位の各要求メッセージに含める。
message FooRequestOptions { // フィールドレベル読み取りマスク。要求されたフィールドのみ返す。 // クライアントは(バックエンドが要求を最適化するために)必要なフィールドのみ要求 optional FooReadMask read_mask; // 最大でこの数のコメントが返す。 // スパムとしてマークされたコメントは、最大コメント数にカウントされない。 // デフォルトでは、コメントは返されない。 optional int max_comments_to_return; // このサポートされている型リストにない埋め込みを含むfooは、このリストで指定された埋め込みにダウンコンバートされた埋め込みを持つ。サポートされるタイプリストが指定されない場合、埋め込みは返されない。埋め込みをるサポートされている型のいずれかにダウンコンバートできない場合、埋め込みは返されない。クライアントは、EmbedTypes.protoから少なくともTHING_V2埋め込み型を常に含めることを強くお勧めします。 repeated EmbedType embed_supported_types_list; } message GetFooRequest { // ビューアーがFooにアクセスできない場合、またはFooが削除されている場合、 // 応答は空になるが成功する。 optional string foo_id; // クライアントはこのフィールドを含める必要がある // FooRequestOptions が空のままだと、サーバの返却は INVALID_ARGUMENT になる optional FooRequestOptions params; } message ListFooRequest { // 検索では100%が再現されるが、より多くの句がパフォーマンスに影響する。 optional FooQuery query; // クライアントはこのフィールドを含める必要がある // FooRequestOptionsが空のままだと、サーバーはINVALID_ARGUMENTを返します。 optional FooRequestOptions params; }
Batch/Multi-phase リクエスト
- 可能な限り、Mutations を 原始的なものにする。さらに重要なのは、Mutations を冪等性にすること。部分的な失敗の完全な再試行は、データを破損 したり複製したりしてはならない。
- 時に、パフォーマンス上の理由から、複数の操作をカプセル化した単一の RPC が必要になることがある。部分的な失敗の場合(あるものが成功し、あ るものが失敗した場合)クライアントに知らせるのが一番。
- RPC を failed に設定し、成功と失敗の両方の詳細を RPC status proto で返すことを検討する。
小さなデータを返す/操作するメソッドを作成し、クライアントが複数の要求をまとめて UI を構成することを期待する
1 回のラウンドトリップで多くの厳密に指定されたデータのビット?を照会できるため、クライアントが必要なものを構成することで、サーバーを変更せずに幅広い UX オプションを提供することができる
これは、フロントエンドや middle-tier サーバーに最も関係がある。(多くのサービスが独自のバッチング API を公開している)
モバイルやウェブで連続したラウンドトリップが必要な場合、1 回限りの RPC を作成する
一般的な進化は、1 つの繰り返しフィールドが複数の関連した繰り返しフィールドになる必要があることである。つまり、並列の繰り返しフィールドを作成するか、値を保持する新しいメッセージで新しい繰り返しフィールドを定義し、クライアントをそのフィールドに移行するかである。
繰り返しのメッセージから始めると、進化は些細なことになる
// 写真に適用される補正の種類 enum EnhancementType { ENHANCEMENT_TYPE_UNSPECIFIED; RED_EYE_REDUCTION; SKIN_SOFTENING; } message PhotoEnhancement { optional EnhancementType type; } message PhotoEnhancementReply { // Good: PhotoEnhancementは、enumだけでなく、 // より多くのフィールドを必要とする拡張機能を記述して成長可能 repeated PhotoEnhancement enhancements; // Bad: もし、エンハンスメントに関連するパラメータを返したい場合は、 // 並列配列を導入するか(酷い)、このフィールドを非推奨とし、繰り返しメッセージを導入する必要がある。 repeated EnhancementType enhancement_types; }
例外:
- レイテンシが重要なアプリケーションでは、プリミティブ型の並列配列の方がメッセージの単一配列よりも構築と削除が高速である
- また
[packed=true](フィールドタグを除外する) を使用する場合は、ネットワーク上で小さくすることもできる。固定数の配列を割り当てる方が、N 個のメッセージを割り当てるよりも手間がかからない。※Proto 3 では packing は自動;明示的に指定する必要はありません。
Proto Maps を使用する
- proto3 からは
Map<scalar, **message**>を使用する - 事前に構造がわからない任意のデータを表す場合は、google.protobuf.Any を使用
冪等性を優先
- クライアントが再試行ロジックを持つ場合がある。
- 再試行が Mutations である場合、データ重複などに繋がる。
- 重複書き込みを避ける簡単な方法は、クライアントが作成したリクエスト ID を指定できるようにすることで、サーバーがそれを元に重複排除すること(例えば、コンテンツのハッシュや UUID など)。
サービス名はグローバル(ネットワーク上)でユニークなものにする
- サービス名(つまり、.proto ファイルの service キーワードの後の部分)は、サービスクラス名を生成するためだけでなく、意外と多くの場所で使われる。そのため、この名前は重要。
- 厄介なのは、これらのツールは、サービス名がネットワーク上で一意であるという暗黙の前提を置いていること。さらに悪いことに、これらのツールが使用するサービス名は、修飾されたサービス名(例:my_package.MyService)ではなく、修飾されていないサービス名(例:MyService)です。
- このため、たとえ特定のパッケージ内で定義されたサービスであっても、サービス名の命名衝突を防ぐための措置を講じることが理にかなっている。例えば、Watcher という名前のサービスは問題を起こす可能性が高いため、MyProjectWatcher のようなものが良い。
すべての RPC で(許可制の)期限を指定して強制する
- デフォルトでは、RPC はタイムアウトを持たない。リクエストは完了時にのみ解放される。
- バックエンドリソースを占有するかもしれないため、すべてのリクエストが終了できるようにデフォルトの期限を設定することは良い防御方法。(過去には、これを実施しなかったために、主要なサービスにおいて深刻な問題が発生したこともある)
- RPC クライアントは、発信する RPC に期限を設定すべきであり、標準的なフレームワークを使用する場合は、通常デフォルトで設定される。
- デッドラインは、リクエストに付けられたより短いデッドラインによって上書きされることがあり、通常は上書きされる。
rpc Foo(FooRequest) returns (FooResponse) { option deadline = x; // グローバルに通用するデフォルトは存在しない }
リクエストサイズとレスポンスサイズの境界
- リクエストとレスポンスのサイズには上限を設ける必要がある
- 8MiB 程度の制限を推奨。2GiB は多くの proto の実装が壊れるハードリミット
- 無制限のメッセージは
- クライアントとサーバーの双方を肥大化させる
- 予測不可能な高いレイテンシーを引き起こす
- 単一クライアントと単一サーバー間の長時間接続に依存することで、回復性を低下させる
- API 内のすべてのメッセージを境界付けるいくつかの方法
ステータスコードの伝搬は慎重に
RPC サービスは、エラーを調査するために RPC 境界で注意を払い、意味のあるステータスエラーを呼び出し元に返す必要がある
例:
引数をとらない ProductService.GetProducts を呼び出すクライアントを考える。 GetProducts の一部として、ProductService はすべての製品を取得し、各製品に対して LocaleService.LocaliseNutritionFacts を呼び出すかもしれな い。
digraph toy_example {
node [style=filled]
client [label="Client"];
product [label="ProductService"];
locale [label="LocaleService"];
client -> product [label="GetProducts"]
product -> locale [label="LocaliseNutritionFacts"]
}
ProductService の実装が不適切な場合、LocaleService に誤った引数を送信し、INVALID_ARGUMENT が発生する可能性がある。
ProductService が不用意に呼び出し側にエラーを返すと、ステータスコードが RPC 境界を越えて伝播するため、クライアントは INVALID_ARGUMENT を受け取る。しかし、クライアントは ProductService.GetProducts に何の引数も渡していない。つまり、このエラーは役に立たないどころか、大きな混乱を招くことになる
その代わりに、ProductService は、RPC 境界(つまり、実装している ProductService RPC ハンドラ)で受け取ったエラーを照会する必要がある。呼び 出し元から無効な引数を受け取った場合は、INVALID_ARGUMENT を返すようにする。下流のものが無効な引数を受け取った場合、INVALID_ARGUMENT を INTERNAL に変換してから呼び出し元にエラーを返すべきである。
不用意にステータスエラーを伝播させると、混乱を招き、デバッグに多大なコストがかかることになる。さらに悪いことに、すべてのサービスがクライアントエラーを転送し、何のアラートも発生させないという、見えない停止につながる可能性がある。
一般的なルールとして、RPC の境界では、エラーを問い合わせ、適切なステータスコードで、意味のあるステータスエラーを呼び出し側に返すように注意する。意味を伝えるために、各 RPC メソッドは、どのような状況でどのようなエラーコードを返すかを文書化する必要がある。各メソッドの実装は、文 書化された API 契約に準拠する必要がある。
Reapeated フィールドの Tips
Repeated フィールド の返し方
- repeated フィールドには hasXxx メソッドは存在しない(repeated フィールドが空の場合、クライアントはそのフィールドがサーバによって入力されなかっただけか、フィールドのバッキングデータが本当に空なのか判断できない)
- 対処:メッセージ内の repeated フィールドをラップすることは、hasXxx メソッドの代替となる
message FooList { repeated Foo foos; }
- より全体的な解決方法は、フィールド読み取りマスクを使用すること
- フィールドが要求された場合、空のリストはデータがないことを意味する。
- フィールドが要求されなかった場合、クライアントは応答のフィールドを無視する必要がある。
Repeated フィールドの修正(更新)
Bad:クライアントに代替リストを供給することを強制すること。
- クライアントに配列全体の供給を強制することの危険性は何倍にもなる。
- 不明なフィールドを保持しないクライアントは、データ損失の原因となります。
- 同時書き込みはデータ損失の原因となる。
- これらの問題が当てはまらない場合でも、クライアントはドキュメントを注意深く読み、サーバー側でフィールドがどのように解釈されるかを知る必要がある。
修正方法
- 繰り返し更新のマスクを使用し、書き込み時に配列全体を供給することなく、クライアントが配列に要素を置換、削除、挿入できるようにする。
- リクエストプロトで、append, replace, delete の各配列を個別に作成する。
- リクエストでは、追加またはクリアのみを許可する。
- これを行うには、repeated フィールドをメッセージでラップする。
- メッセージがあるが空であればクリア、そうでなければ repeated 要素は追加を意味する。
repeated フィールドにおける順序の非依存性
message BatchEquationSolverResponse { // Bad: 解決された値は、リクエストで指定された方程式の順序で返される repeated double solved_values; // (Usually) Bad: solved_valuesの並列配列 repeated double solved_complex_values; } // Good: より多くのフィールドを含むように成長し、他のメソッド間で共有できる独立したメッセージ // リクエストとレスポンスの間の順序依存性が なく、複数のrepeatedフィールド間の順序依存性がない message BatchEquationSolverResponse { // 非推奨。2014年第2四半期までは、この項目が回答として入力され続ける。 repeated double solved_values [deprecated = true]; // Good: リクエストの各方程式には一意の識別子があり、 // 以下のEquationSolutionに含まれている一意の識別子があり、解答は方程式そのものと関連付けることができる。方程式は並行して解かれ、解が作 られるとこの配列に追加される。 repeated EquationSolution solutions; }
パフォーマンスの最適化
場合によっては、型の安全性や明確性を性能の向上と引き換えにすることができる。
例えば
- 何百ものフィールド、特にメッセージ型フィールドを持つプロトは、より少ないフィールドを持つものよりも解析が遅くなる。
- 非常に深くネストされたメッセージは、メモリ管理だけでデシリアライズに時間がかかることがある。
デシリアライズを高速化するためのテクニック:
- 大きなプロトをミラーリングするが、一部のタグのみを持ち、平行にトリミングされたプロトを作成する。
- これを、すべてのフィールドが必要でない場合の解析に使用する。
- トリミングされたプロトはナンバリングの "穴 "が蓄積していくため、タグの番号が一致し続けることを強制するテストを追加する。
[lazy=true]でフィールドを "lazily parsed "として注釈をつける。- フィールドをバイトとして宣言し、その型を文書化する。フィールドを解析しようとするクライアントは、手動でそれを行うことができる。
- この方法の危険性は、誰かが間違った型のメッセージを bytes フィールドに入れることを防ぐものがないこと。
- PII のためにプロトが吟味されたり、ポリシーやプライバシーのためにスクラブされたりするのを防ぐため、ログに書き込まれるプロトでは決してこの方法を取るべきではない
ref:
GraphQL Code Generator まとめ
GraphQL Code Generator まとめ
公式ドキュメント:
- https://the-guild.dev/graphql/codegen
- 設定ファイル: https://the-guild.dev/graphql/codegen/docs/config-reference/codegen-config
- プラグイン: https://the-guild.dev/graphql/codegen/plugins/typescript/typescript
インストール&セットアップ
npm install graphql npm install -D typescript npm install -D @graphql-codegen/cli
セットアップ(全てデフォルト指定)
$ npx graphql-code-generator init
Welcome to GraphQL Code Generator!
Answer few questions and we will setup everything for you.
? What type of application are you building? Application built with React
? Where is your schema?: (path or url) http://localhost:4000
? Where are your operations and fragments?: src/**/*.tsx
? Where to write the output: src/gql
? Do you want to generate an introspection file? Yes
? How to name the config file? codegen.ts
? What script in package.json should run the codegen? codegen
Fetching latest versions of selected plugins...
(node:224940) ExperimentalWarning: buffer.Blob is an experimental feature. This feature could change at any time
(Use `node --trace-warnings ...` to show where the warning was created)
Config file generated at codegen.ts
$ npm install
To install the plugins.
$ npm run codegen
To run GraphQL Code Generator.
生成された codegen.ts
import type { CodegenConfig } from "@graphql-codegen/cli";
const config: CodegenConfig = {
overwrite: true,
schema: "http://localhost:4000",
documents: "src/**/*.tsx",
generates: {
"src/gql": {
preset: "client",
plugins: [],
},
"./graphql.schema.json": {
plugins: ["introspection"],
},
},
};
export default config;
設定ファイル
https://the-guild.dev/graphql/codegen/docs/config-reference/codegen-config
設定ファイル生成
npx graphql-code-generator --config ./path/to/codegen.ts
例(複数指定):
import { CodegenConfig } from "@graphql-codegen/cli";
const config: CodegenConfig = {
// documents: ['src/**/*.tsx', '!src/gql/**/*'],
generates: {
"./src/gql/github/": {
schema: "https://docs.github.com/public/schema.docs.graphql",
preset: "client",
plugins: [],
},
"./src/gql/gitlab/": {
schema: "https://gitlab.com/api/graphql?remove_deprecated=true",
preset: "client",
plugins: [],
},
},
overwrite: true,
};
export default config;
documents (GraphQL Document とは)
gql を定義しているファイルを指定する。指定することで Query や Mutations 等の型が生成される。※ 名前付け必須。なければ自動生成対象にならない
GraphQL Document:
- GraphQL へ投げる query やら mutation やらの string のことを指す
- 具体的には、 gql に渡している部分
const GET_GREETING = gql`
query GetGreeting($language: String!) {
greeting(language: $language) {
message
}
}
`;
ref: https://zenn.dev/link/comments/600791d07ec1a1
namingConvention
出力の命名規則をオーバーライドできる
- デフォルト:change-case-all#pascalCase
- lower、upper、camel、pascal 等変更できる
- 範囲指定:typeNames、enumValues
- "keep"を使用してすべての GraphQL 名をそのまま保持することもできる(例:
enumValues: 'keep') - アンダースコアを保持する場合は、transformUnderscore を true に設定
import { CodegenConfig } from "@graphql-codegen/cli";
const config: CodegenConfig = {
// ...
config: {
namingConvention: {
typeNames: "change-case-all#pascalCase",
enumValues: "change-case-all#upperCase",
},
},
// ...
};
export default config;
ref: https://the-guild.dev/graphql/codegen/docs/config-reference/naming-convention
Lifecycle Hooks
codegen で、特定のイベントで実行できるスクリプトを指定可能
import { CodegenConfig } from "@graphql-codegen/cli";
const config: CodegenConfig = {
schema: "http://localhost:4000/graphql",
documents: ["src/**/*.tsx"],
generates: {
"./src/gql/": {
preset: "client",
},
},
//
hooks: {
afterOneFileWrite: ["prettier --write"],
},
};
export default config;
hooks 一覧:
- afterStart:
- onWatchTriggered:
- ウォッチモード使用時に、ファイルが変更されるたびにトリガー。イベントのタイプ(例:changed)とファイルのパスの 2 つの引数でトリガー。
- onError:
- codegen に一般的なエラーが発生した場合にトリガー。引数はエラーを含む文字列である。
- beforeAllFileWrite:
- beforeOneFileWrite:
- ファイルがファイルシステムに書き込まれる前にトリガー。ファイルのパスで実行される。 前回実行時からファイルの内容が変化していない場合、このフックは発動しない。
- afterOneFileWrite:
- ファイルがファイルシステムに書き込まれた後にトリガー。ファイルのパスを指定して実行される。ファイルの内容が前回の実行から変更されていない場合、このフックはトリガーされない。
- afterAllFileWrite:
- すべてのファイルをファイルシステムに書き込んだ後に実行されます。複数の引数 (すべてのファイルのパス) でトリガー。
- beforeDone:
- 引数なしで、codegen が閉じる直前、またはウォッチモードが停止したときにトリー。
出力先単位で指定できるのは以下のみ。他はルートのみ指定可能。
beforeOneFileWriteafterOneFileWrite
プラグイン
- typescript :GraphQL スキーマに基づいて基本 TypeScript タイプを生成
- @graphql-codegen/typescript-operations:
- GraphQL Schema と GraphQL の操作とフラグメントに基づいて TypeScript 型を生成。
- GraphQL ドキュメントの型を生成:Query、Mutation、Subscription、Fragment
- @graphql-codegen/typescript-urql : urql 用。 ref: urql をさわってみるぞ
※ apollo の場合は以下っぽい
plugins: - "typescript" - "typescript-operations" - "typescript-react-apollo"
コード自動生成
- GraphQL スキーマからコード自動生成:
モック データ生成プラグイン:
※Github と Gitlab のスキーマから自動生成サンプル
import { CodegenConfig } from "@graphql-codegen/cli"; const config: CodegenConfig = { generates: { "./src/gql/github/": { schema: "https://docs.github.com/public/schema.docs.graphql", documents: "src/data/github/github-queries.ts", preset: "client", plugins: [], // 'typescript'を入れると型が2重出力される }, "./src/gql/gitlab/": { schema: "https://gitlab.com/api/graphql?remove_deprecated=true", documents: "src/data/gitlab/gitlab-queries.ts", preset: "client", plugins: [], // 'typescript'を入れると型が2重出力される }, "./src/mocks/github/mock.ts": { schema: "https://docs.github.com/public/schema.docs.graphql", plugins: [ { "typescript-mock-data": { typesFile: "src/gql/github/graphql.ts", prefix: "mockGithub", terminateCircularRelationships: true, // 循環関係による無限再帰防止 }, }, ], }, "./src/mocks/gitlab/mock.ts": { schema: "https://gitlab.com/api/graphql?remove_deprecated=true", plugins: [ { "typescript-mock-data": { typesFile: "src/gql/gitlab/graphql.ts", prefix: "mockGitlab", terminateCircularRelationships: true, // 循環関係による無限再帰防止 }, }, ], }, }, overwrite: true, }; export default config;
gql
export const GET_GITHUB_REPOSITORIES = gql` query GetGithubRepositories($owner: String!) { user(login: $owner) { repositories(last: 10) { nodes { name url } } } } `;
msw の handlers.ts
// path: src/mocks import { graphql } from "msw"; // GET_GITHUB_REPOSITORIES から 生成された type import { GetGithubRepositoriesDocument } from "src/gql/github/graphql"; // User モックデータ生成関数 import { mockGithubUser } from "./github/mock"; export const handlers = [ graphql.query(GetGithubRepositoriesDocument, (req, res, ctx) => { return res( ctx.data({ // 引数で値の上書き、返す関連データの指定が可能 user: mockGithubUser(), }) ); }), ];